Groq: การปฏิวัติ AI Inference ด้วยความเร็วสุดขีด
Groq คืออะไร? Groq เป็นแพลตฟอร์ม Fast AI Inference ที่รองรับโมเดล open-source ยอดนิยม เช่น Llama, DeepSeek, Mixtral, Qwen, Whisper และอื่นๆ บริษัทก่อตั้งในปี 2016 เพื่อสร้างเทคโนโลยีที่ตอบสนองความต้องการด้าน AI inference ที่เติบโตอย่างรวดเร็ว
หัวใจสำคัญของ Groq คือ LPU ซึ่งแตกต่างจาก GPU แบบดั้งเดิม:
- LPU™ Inference Engine เป็นแพลตฟอร์มฮาร์ดแวร์และซอฟต์แวร์ที่ให้ความเร็วในการคำนวณ คุณภาพ และประสิทธิภาพพลังงานที่เหนือกว่า
- LPU ถูกออกแบบมาเฉพาะสำหรับการประมวลผลภาษา แตกต่างจาก GPU ที่ออกแบบมาสำหรับการประมวลผลกราฟิก
- Compute และ memory อยู่บนชิปเดียวกัน ลดปัญหาคอขวด
- Compiler ควบคุมการทำงาน แทนที่จะเป็นรองต่อฮาร์ดแวร์
- ผู้ทดสอบได้ความเร็วมากกว่า 300 tokens ต่อวินาที เร็วกว่า GPT-4 บน ChatGPT
- เร็วกว่า GPU ถึง 18 เท่า ในการ inference ของ language models
- ให้ throughput สูงถึง 4 เท่าเมื่อเทียบกับบริการ inference อื่นๆ
ใช้พลังงานเพียง 1-3 joules ต่อ token เทียบกับ Nvidia GPU ที่ใช้ 10-30 joules ต่อ token คือเร็วกว่า 10 เท่าและประหยัดพลังงาน 10 เท่า หรือดีกว่า 100 เท่าในแง่ price/performance
สามารถย้ายจากผู้ให้บริการอื่น เช่น OpenAI ได้ง่ายๆ โดยเปลี่ยนเพียง 3 บรรทัดโค้ด - ตั้ง OPENAI_API_KEY เป็น Groq API Key, กำหนด base URL, และเลือกโมเดล
- Llama 3.1 (8B, 70B)
- Mixtral 8x7B
- Gemma 2 9B
- DeepSeek
- Qwen
- Whisper (สำหรับ speech-to-text)
- ความเร็วสุดขีด - เหมาะสำหรับ real-time applications
- ประหยัดต้นทุน - price/performance ดีกว่าแบบดั้งเดิม
- ง่ายต่อการใช้งาน - API เข้ากันได้กับ OpenAI
- ประหยัดพลังงาน - เป็นมิตรต่อสิ่งแวดล้อม
- รองรับโมเดล open-source - ไม่ติดกับโมเดลเจ้าใดเจ้าหนึ่ง
Groq เป็นตัวเลือกที่น่าสนใจสำหรับคนที่ต้องการ:
- ความเร็วสูง ในการ AI inference
- ประหยัดต้นทุน เมื่อเทียบกับ GPU แบบดั้งเดิม
- ใช้งานง่าย โดยไม่ต้องเปลี่ยน code มาก
- ยืดหยุ่น ในการเลือกโมเดล open-source
เหมาะมากสำหรับการทดลองใช้โมเดลขนาดใหญ่โดยไม่ต้องลงทุนฮาร์ดแวร์เองแต่ได้ประสิทธิภาพสูง!
- view:2

สรุปประเด็นร้อน: Tom Segura และ Christina Pazsitzky แยกทางกันหลัง 18 ปี
รายงานข่าวช็อกวงการคอมเมดี้สหรัฐฯ เมื่อคู่รักนักแสดงตลกชื่อดัง Tom Segura และ Christina Pazsitzky ตัดสินใจแยกทางกันหลังจากแต่งงานมานานกว่า 18 ปี พร้อมผลกระทบต่อพอดแคสต์ยอดนิยม Your Mom's House
- view:6

เช็กเลย! สำนักงาน ก.พ. ประกาศผลสอบภาค ก (e-Exam) ประจำปี 2569 แล้ววันนี้
ช่องทางการตรวจผลสอบ ก.พ. 69 รอบ e-Exam พร้อมขั้นตอนการพิมพ์หนังสือรับรองผลการสอบผ่าน เพื่อใช้ประกอบการสมัครงานราชการ
- view:2

โค้งสุดท้าย! ขยายเวลาลงทะเบียนเลือกตั้งบอร์ดประกันสังคม 2569 ถึง 20 ก.ค. นี้
สรุปขั้นตอนและช่องทางการลงทะเบียนเลือกตั้งคณะกรรมการประกันสังคม (บอร์ดประกันสังคม) ประจำปี 2569 เพื่อกำหนดทิศทางกองทุนและสิทธิประโยชน์ของผู้ประกันตน
- view:701
Groq: การปฏิวัติ AI Inference ด้วยความเร็วสุดขีด
Groq คืออะไร? Groq เป็นแพลตฟอร์ม Fast AI Inference ที่รองรับโมเดล open-source ยอดนิยม เช่น Llama, DeepSeek, Mixtral, Qwen, Whisper และอื่นๆ บริษัทก่อตั้งในปี 2016 เพื่อสร้างเทคโนโลยีที่ตอบสนองความต้องการด้าน AI inference ที่เติบโตอย่างรวดเร็ว
- view:657
Supermemory MCP: เครื่องมือช่วยจำอัจฉริยะสำหรับ AI ของคุณ
Supermemory MCP (Personal, Universal Memory) คือเครื่องมือช่วยจำส่วนตัวที่ใช้งานได้หลากหลายรูปแบบ ซึ่งช่วยให้คุณสามารถนำข้อมูลที่คุณกำลังใช้งาน (context) ติดตัวไปกับเครื่องมือและแอปพลิเคชัน AI ต่างๆ ได้อย่างต่อเนื่อง
- view:426

Odyc.js: สร้างเกมง่ายๆ แม้ไม่มีประสบการณ์เขียนโค้ด
Odyc.js คือไลบรารี JavaScript ขนาดเล็กที่ออกแบบมาเพื่อช่วยให้คุณสร้างวิดีโอเกมได้ง่ายๆ จุดเด่นคือ คุณสามารถเริ่มเขียนโค้ดสร้างเกมได้เลย แม้ว่าจะไม่เคยมีประสบการณ์การเขียนโปรแกรมมาก่อนก็ตาม
- view:887

TON
TON (The Open Network) คืออินเทอร์เน็ตแบบใหม่ที่สร้างขึ้นโดยชุมชน โดยใช้เทคโนโลยีที่เคยพัฒนาโดย Telegram เป้าหมายหลักคือการช่วยให้คน 500 ล้านคนทั่วโลกได้รู้จักและใช้งานบล็อกเชน
- view:922

TOPS
TOPS ในบริบทของ AI (Artificial Intelligence) มักย่อมาจาก “Tera Operations Per Second” หรือ “จำนวนทศล้านล้านคำสั่งต่อวินาที” ซึ่งเป็นหน่วยวัด ความสามารถในการประมวลผล ของฮาร์ดแวร์ (เช่น ชิปประมวลผล, GPU, NPU หรือหน่วยประมวลผลอื่น ๆ) ว่าสามารถคำนวณหรือประมวลผลด้าน AI ได้มากน้อยแค่ไหนในหนึ่งวินาที
- view:1068
DocuSeal
DocuSeal เป็นแพลตฟอร์มโอเพนซอร์สสำหรับการลงนามเอกสารดิจิทัลที่ใช้งานง่ายและปลอดภัย ผู้ใช้สามารถสร้าง แก้ไข และลงนามเอกสารออนไลน์ได้อย่างสะดวก โดยมีฟีเจอร์เด่น เช่น การสร้างฟอร์ม PDF ที่ปรับแต่งได้ การสนับสนุนผู้ลงนามหลายคน การส่งอีเมลอัตโนมัติ และการลงนามอิเล็กทรอนิกส์ที่เป็นไปตามมาตรฐาน
- view:1023
Mermaid
Mermaid เป็นเครื่องมือสร้างไดอะแกรมและแผนภูมิที่ใช้ JavaScript โดยใช้การกำหนดไวยากรณ์ที่คล้ายกับ Markdown เพื่อสร้างและปรับปรุงไดอะแกรมที่ซับซ้อนได้อย่างง่ายดาย
- view:1057
VineJS
VineJS เป็นไลบรารีสำหรับการตรวจสอบความถูกต้องของข้อมูลฟอร์มใน Node.js โดยคุณสามารถใช้เพื่อยืนยันความถูกต้องของข้อมูลที่ได้รับจาก HTTP request body ในแอปพลิเคชันฝั่งเซิร์ฟเวอร์ของคุณ VineJS มีประสิทธิภาพสูงและเป็นหนึ่งในไลบรารีการตรวจสอบความถูกต้องที่เร็วที่สุดในระบบนิเวศของ Node.js
- view:1059
Appwrite
Appwrite เป็นแพลตฟอร์มโอเพนซอร์สสำหรับการสร้างแอปพลิเคชัน Backend-as-a-Service (BaaS) ที่ช่วยให้นักพัฒนาสามารถจัดการส่วนหลังบ้านของเว็บหรือแอปพลิเคชันมือถือได้ง่ายขึ้น โดย
- view:1039

Illlustrations
เป็นไลบรารีภาพประกอบแบบโอเพนซอร์สที่มีภาพประกอบมากกว่า 120 แบบ
- view:1096
Roadmap.sh
เป็นแพลตฟอร์มโอเพนซอร์สที่ช่วยแนะนำและให้คำแนะนำในเส้นทางการเรียนรู้สำหรับนักพัฒนาซอฟต์แวร์
- view:989
Farm
เป็นเครื่องมือสร้างเว็บที่ทำงานได้อย่างรวดเร็วและถูกพัฒนาด้วย Rust
- view:906
Shadcn UI
เป็นชุดคอมโพเนนต์สำหรับ React ที่ช่วยให้นักพัฒนาสามารถคัดลอกและวางโค้ดลงในโปรเจกต์ของตนได้โดยตรง
- view:858
EldoraUI
เป็นไลบรารี UI แบบโอเพนซอร์ส ที่รวบรวมคอมโพเนนต์แอนิเมชันขนาดเล็กที่สามารถใช้งานซ้ำได้
- view:803
Framer Ground
เป็นแพลตฟอร์มที่นำเสนอชุดคอมโพเนนต์ขนาดเล็กที่มีแอนิเมชัน สำหรับการสร้างเว็บโปรเจกต์ที่มีความสวยงามและตอบสนองได้ดี
- view:831
FakeStoreAPI
เป็น API ที่ให้บริการข้อมูลสินค้าและร้านค้าเสมือนจริง
- view:918
DuckDB
เป็นระบบฐานข้อมูลที่ออกแบบมาสำหรับการวิเคราะห์ข้อมูลในแบบ OLAP (Online Analytical Processing)
- view:911

Loco.rs
เป็นเว็บเฟรมเวิร์กที่ได้รับแรงบันดาลใจจาก Ruby on Rails
- view:668
Pocketbase: พื้นฐานสำหรับการพัฒนาแอปพลิเคชันออนไลน์
ในยุคที่เทคโนโลยีการสื่อสารก้าวหน้าไปอย่างรวดเร็ว การสร้างแอปพลิเคชันออนไลน์ที่ทันสมัยและตอบสนองความต้องการของผู้ใช้เป็นสิ่งที่ทุกองค์กรต่างให้ความสำคัญ เครื่องมือที่ถูกนำมาใช้เพื่อตอบโจทย์นี้คือ Pocketbase ซึ่งเป็นเครื่องมือพัฒนาแอปพลิเคชันขนาดเล็กแต่มีพลังอันยิ่งใหญ่
- view:896

opencollective คืออะไร
ในยุคที่โลกเข้าสู่ยุคดิจิทัลอย่างเต็มตัว ปัญหาต่างๆ ไม่ว่าจะเป็นทางด้านสังคม เศรษฐกิจ หรือแม้แต่สิ่งแวดล้อม ก็ล้วนแต่มีความซับซ้อนมากขึ้น ซึ่งไม่สามารถแก้ไขด้วยวิธีการแบบเดิมๆ ได้อีกต่อไป การหาแนวทางใหม่ๆ ในการแก้ไขปัญหาสาธารณะจึงเป็นสิ่งที่จำเป็นอย่างยิ่ง และ Open Collective คือหนึ่งในแนวทางที่น่าสนใจ
- view:953

Angular v18
Angular v18 เปิดตัวพร้อมกับการปรับปรุงและฟีเจอร์ใหม่หลายอย่างที่ออกแบบมาเพื่อยกระดับประสบการณ์ของนักพัฒนาซอฟต์แวร์ โดยฟีเจอร์เด่นได้แก่การปรับปรุงระบบการทำงานของสัญญาณ (Signals) การปรับปรุงการแสดงผลฝั่งเซิร์ฟเวอร์ (SSR) และการสนับสนุน Material Design 3 (M3)
- view:1008

Burn - Deep Learning Framework
เป็นเฟรมเวิร์กสำหรับ Deep Learning ที่สร้างขึ้นโดยใช้ภาษา Rust โดยมีเป้าหมายหลักเพื่อให้เกิดความ ยืดหยุ่น (flexibility), ประสิทธิภาพ (performance), และ ความสามารถในการพกพา (portability) ที่สูงสุด เฟรมเวิร์กนี้ถูกออกแบบมาเพื่อรองรับทั้งการฝึกอบรม (training) และการคาดคะเน (inference) ของโมเดล machine learning โดยมุ่งเน้นไปที่การทำงานร่วมกับฮาร์ดแวร์ที่หลากหลาย เช่น CPU, GPU, และ WebAssembly
- view:991

NocoDB
NocoDB คือแพลตฟอร์มโอเพนซอร์สที่ใช้ในการแปลงฐานข้อมูล SQL เช่น MySQL, PostgreSQL, SQLite, Microsoft SQL Server และอื่นๆ ให้กลายเป็นฐานข้อมูลที่สามารถจัดการได้ในลักษณะของสเปรดชีต (Spreadsheet-like interface) คล้ายกับ Airtable ซึ่งช่วยให้ผู้ใช้ที่ไม่จำเป็นต้องมีความรู้ทางเทคนิคสูงสามารถจัดการข้อมูลในฐานข้อมูลได้อย่างง่ายดายผ่านอินเทอร์เฟซที่ใช้งานง่าย
- view:979

FreeBSD
FreeBSD เป็นระบบปฏิบัติการแบบ Unix-like ที่มีความเสถียรและปลอดภัยสูง ซึ่งเป็นที่นิยมในหมู่นักพัฒนาซอฟต์แวร์และผู้ดูแลระบบ โดยเฉพาะในงานที่ต้องการประสิทธิภาพ ความเสถียร และความปลอดภัยสูง เช่น เซิร์ฟเวอร์เว็บ ไฟร์วอลล์ และระบบเครือข่าย
- view:883

Prisma 5.19.0
Prisma 5.19.0 มาพร้อมกับฟีเจอร์ใหม่และการปรับปรุงหลายอย่างที่น่าสนใจ โดยมีจุดเด่นดังนี้
- view:1145

Tempus AI Inc
เป็นบริษัทเทคโนโลยีด้านสุขภาพจากสหรัฐอเมริกา ก่อตั้งขึ้นในปี 2015 โดย Eric Lefkofsky เพื่อตอบสนองต่อประสบการณ์ส่วนตัวเมื่อภรรยาของเขาถูกวินิจฉัยว่าเป็นมะเร็งเต้านม บริษัทนี้เน้นการใช้ปัญญาประดิษฐ์ (AI) และข้อมูลขนาดใหญ่ในการสร้างโซลูชั่นด้านการแพทย์แม่นยำ (Precision Medicine) โดยมุ่งเน้นไปที่การวินิจฉัย การพัฒนายา และการรักษาผู้ป่วยอย่างมีประสิทธิภาพ
- view:973

Polestar Automotive Holding UK PLC (PSNY)
เป็นบริษัทที่มีต้นกำเนิดจากสวีเดน และดำเนินธุรกิจหลักในการผลิตและจำหน่ายรถยนต์ไฟฟ้าหรู (electric vehicles หรือ EVs) โดยบริษัทนี้เกิดจากความร่วมมือระหว่าง Volvo Cars และ Geely Holding Group
- view:946

MEDIROM Healthcare Technologies Inc. (MRM)
เป็นบริษัทที่ให้บริการด้านสุขภาพและความเป็นอยู่ที่ดี โดยมีฐานการดำเนินงานหลักในประเทศญี่ปุ่น บริษัทนี้ก่อตั้งขึ้นเพื่อมุ่งเน้นการพัฒนาผลิตภัณฑ์และบริการที่ช่วยส่งเสริมสุขภาพและการใช้ชีวิตที่มีคุณภาพในกลุ่มลูกค้า โดยเฉพาะในด้านการผ่อนคลายและฟื้นฟูสุขภาพ
- view:890
Project IDX คืออะไร
Project IDX เป็นสภาพแวดล้อมการพัฒนาแบบรวมทุกอย่าง (Integrated Development Environment: IDE) ที่ทำงานบนเว็บทั้งหมด โดยถูกพัฒนาขึ้นโดย Google โดยมีวัตถุประสงค์หลักเพื่อทำให้การพัฒนาแอปพลิเคชันแบบเต็มสแต็กและหลายแพลตฟอร์มเป็นเรื่องง่ายและสะดวกมากยิ่งขึ้น ด้วย Project IDX นักพัฒนาสามารถสร้างและปรับใช้แอปพลิเคชันในเทคโนโลยีต่าง ๆ ได้โดยไม่ต้องจัดเตรียมสภาพแวดล้อมการพัฒนาด้วยตัวเอง เนื่องจาก IDX ทำงานบนเครื่องเสมือนที่ตั้งค่าไว้ล่วงหน้าบน Google Cloud เพื่อให้การพัฒนานั้นมีความน่าเชื่อถือ ปลอดภัย และสามารถปรับแต่งได้เหมือนกับสภาพแวดล้อมการพัฒนาท้องถิ่น
- view:676

Jpegli เป็นไลบรารีการเข้ารหัสภาพ JPEG ล่าสุดจาก Google
Jpegli เป็นไลบรารีการเข้ารหัสภาพ JPEG ล่าสุดจาก Google ที่มีจุดมุ่งหมายเพื่อปรับปรุงประสิทธิภาพการบีบอัดภาพให้ดียิ่งขึ้น พร้อมกับการรักษาความเข้ากันได้สูงกับมาตรฐาน JPEG แบบดั้งเดิม ด้วยการใช้เทคนิคที่ล้ำสมัยและเทคโนโลยีใหม่ๆ Jpegli สามารถบีบอัดภาพได้มากขึ้นถึง 35% ในการตั้งค่าการบีบอัดคุณภาพสูง โดยไม่ลดลงคุณภาพของภาพ นอกจากนี้ยังสนับสนุนการเข้ารหัสด้วย 10 บิตหรือมากกว่าต่อส่วนประกอบ ซึ่งช่วยลดปัญหาการปรากฏของ artifacts ในภาพ
- view:620

ซัพพลายเออร์ชิปของ Apple คือ TSMC ได้กล่าวว่าพวกเขาได้กลับมาดำเนินการผลิตชิปส่วนใหญ่แล้ว
ซัพพลายเออร์ชิปของ Apple คือ TSMC ได้กล่าวว่าพวกเขาได้กลับมาดำเนินการผลิตชิปส่วนใหญ่แล้ว หลังจากที่เกิดแผ่นดินไหวขนาด 7.4 ที่ชายฝั่งตะวันออกของไต้หวันเมื่อวันพุธ
- view:682

ซัพพลายเออร์ Apple ระบุ iPad ใหม่ 'ถูกเลื่อนออกไปอย่างต่อเนื่อง'
เมื่อเป็นเวลาประมาณ 18 เดือนที่ Apple ไม่ได้อัปเดตไลน์อัป iPad ของตน ลูกค้าจึงตั้งตารอโมเดลใหม่ๆ มาเป็นเวลาหลายเดือนแล้ว โดยมีข่าวลือเกี่ยวกับ iPad Pro และ iPad Air รุ่นใหม่ แต่กรอบเวลาที่คาดการณ์สำหรับการเปิดตัวของพวกเขาถูกเลื่อนออกไปอย่างต่อเนื่องจากเดือนมีนาคมไปเป็นเดือนเมษายนและต่อไปเป็นเดือนพฤษภาคม
- view:865

ฝนถล่มกรุงเทพ
ติดสนั่น! ระดับน้ำยังไม่ลดลง ถนนเพชรเกษม ขาออก
- view:628

ฝนตกน้ำท่วมแล้ว มอเตอร์เวย์สาย 7
ฝนตกน้ำท่วมแล้ว มอเตอร์เวย์สาย 7
- view:629

ภรรยาของผมไม่ยอมรับการหย่าร้าง
ภรรยาของผมไม่ยอมรับการหย่าร้าง และผมรู้สึกว่าเธอกำลังพยายามหลอกลวงผม ผมจึงตัดสินใจใช้บัญชีที่ซ่อนตัวตนเพราะต้องการคำปรึกษา
- view:1104

อเซ็กชวล (Asexual)
การเข้าใจเรื่องของ "อเซ็กชวล" เป็นสิ่งสำคัญในการรับรู้ถึงความหลากหลายของความสนใจทางเพศและความปรารถนาที่มีอยู่ในสังคมมนุษย์ เรามักจะอยู่ในโลกที่มองเรื่องเพศสัมพันธ์เป็นส่วนสำคัญของความสัมพันธ์และการแสดงออกถึงความรัก อย่างไรก็ตาม ไม่ใช่ทุกคนที่รู้สึกหรือมีความต้องการในเรื่องเพศสัมพันธ์เหมือนกัน บางคนอาจพบว่าตัวเองมีความสนใจหรือความปรารถนาทางเพศน้อยกว่าคนอื่นๆ หรืออาจไม่มีเลย ซึ่งก็ไม่ถือว่าผิดปกติหรือมีปัญหาอะไร
- view:634

การบินความเร็วสูง: การทำลายสถิติใหม่ของไฮเปอร์ลูปจีน
รถไฟแม่เหล็กไฟฟ้าแบบความเร็วสูงของจีน, หรือที่รู้จักกันในชื่อ "ไฮเปอร์ลูป" ของจีน, ได้ทำลายสถิติความเร็วของตัวเองโดยบรรลุความเร็วที่เกินกว่า 623 กิโลเมตรต่อชั่วโมงบนทางทดสอบขนาดเต็มความยาว 2 กิโลเมตรในเมืองต้าตง, มณฑลซานซี ทางตอนเหนือของประเทศจีน. โครงการนี้ดำเนินการโดยบริษัท China Aerospace Science and Industry Corporation (CASIC), บริษัทของรัฐที่ทำธุรกิจตั้งแต่จรวด, ขีปนาวุธ, ถึงดาวเทียมและยานอวกาศ.
- view:672

ใครใช้ iPhone เช็กด่วน‼️ ก่อนโดนดูดเงินเกลี้ยง
ปัจจุบันมีมิจฉาชีพหลอกลวงให้ผู้ใช้ iPhone ติดตั้งแอปฯ ปลอม โดยจะหลอกให้ดาวน์โหลดผ่านช่องทางต่างๆ ไม่ว่าจะเป็น เว็บปลอม, เมลปลอม,SMS ปลอม หรือลิงก์ปลอม ซึ่งในบางครั้งก็อาจจะโหลดมาโดยที่ไม่รู้ตัว ส่วนใหญ่แอปฯ ปลอมจะไม่มีให้โหลดผ่าน App Store และมักจะเลียนแบบแอปจริง เช่น แอปฯ ของหน่วยงานต่างๆ เพื่อดูดข้อมูลส่วนบุคคล ก่อนจะโอนเงินออกจากบัญชี .
- view:736
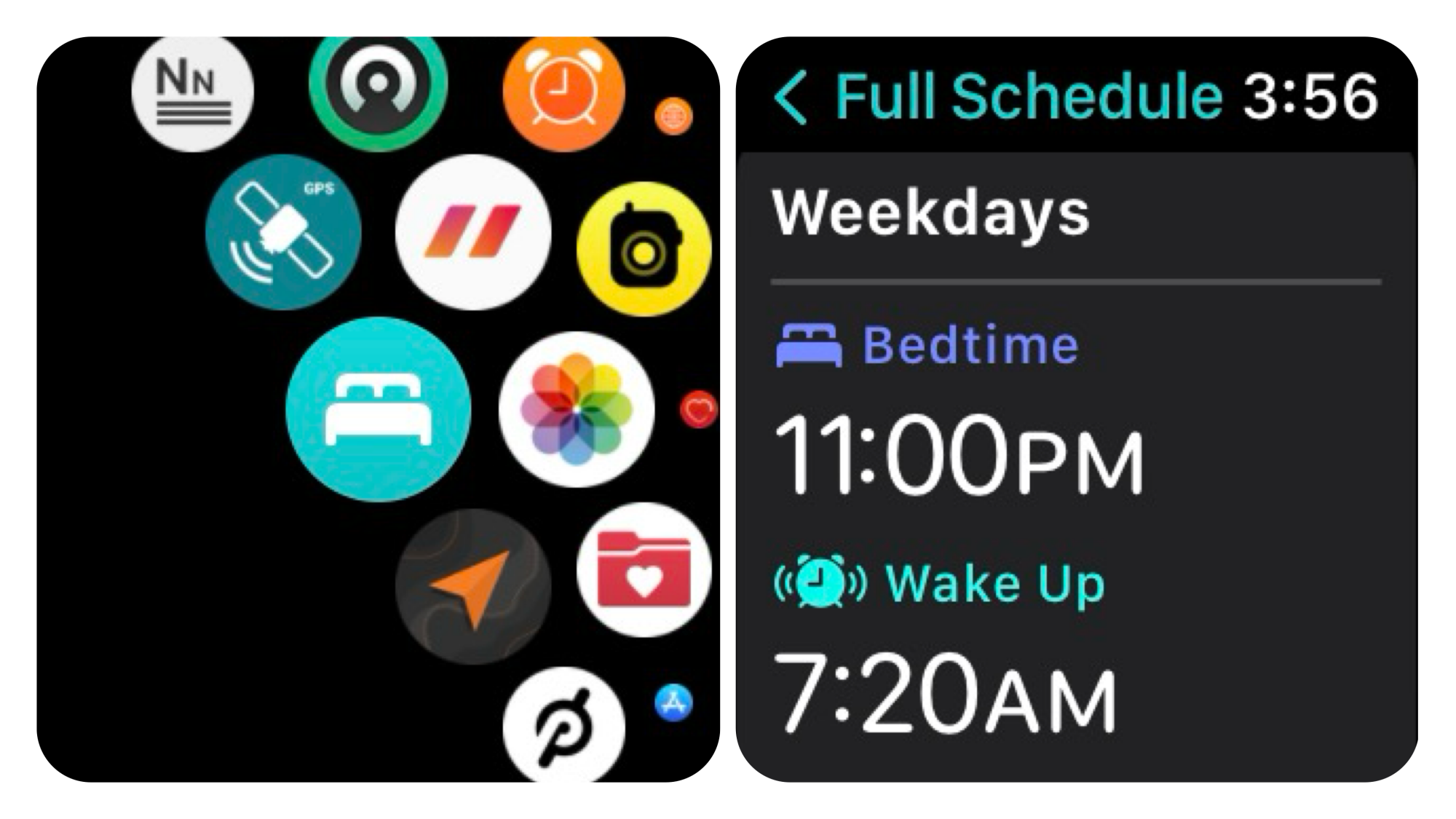
Apple Watch มีคุณสมบัติในการติดตามการนอนหลับภายในตัว
แต่อาจจะไม่ง่ายในการค้นหา นี่คือวิธีการเข้าถึงและตั้งค่าฟีเจอร์การติดตามการนอนหลับบน Apple Watch ของคุณ
- view:798

Apple ขยายการประกอบ iPhone 15 ไปยังบราซิล
Apple ได้เริ่มประกอบ iPhone รุ่น 6.1 นิ้ว 15 ที่ประเทศบราซิล ซึ่งเป็นการขยายการผลิตนอกเหนือจากประเทศจีนที่เป็นฐานการผลิตหลักของบริษัท ตามรายงานจากบล็อก MacMagazine ของบราซิล พบว่า Apple ได้จัดส่ง iPhone 15 ที่ประกอบในบราซิล แม้ว่าบริษัทจะยังไม่ยืนยันข่าวนี้และไม่มีหลักฐานชัดเจนบนเว็บไซต์ของ Apple แต่ในร้านค้าออนไลน์ของ Apple ในบราซิล ลูกค้าสามารถสังเกตุได้จากหมายเลขส่วนท้ายของหน้าเช็คเอาท์ iPhone 15 ที่ลงท้ายด้วย “BR/A” ซึ่งเป็นการระบุผลิตภัณฑ์ที่ประกอบในบราซิล
- view:785

CEO Meta วิพากษ์วิจารณ์ Apple Vision Pro อีกครั้ง
ไม่นานหลังจากที่ Vision Pro เปิดตัว, ซีอีโอของ Meta อย่าง Mark Zuckerberg ได้เผยอย่างชัดเจนว่าเขาเชื่อว่า Quest 3 เป็นชุดหูฟัง VR ที่ดีกว่า, และในช่วงสุดสัปดาห์ที่ผ่านมาเขาได้ใช้ Threads อีกครั้งเพื่อย้ำความเชื่อของเขาว่า Vision Pro ที่มีราคา $3,500 นั้นด้อยกว่า Quest 3 ที่มีราคาเพียง $500
- view:756

2024 iPad Pro: ข่าวลือสำคัญที่ควรรู้
ในช่วงสัปดาห์ที่กำลังจะมาถึง, Apple คาดว่าจะประกาศรุ่นใหม่ของ iPad Pro ซึ่งได้รับความคาดหมายสูงจากลูกค้าอย่างมาก ดังนั้นลูกค้าควรคาดหวังอะไรจากเครื่องใหม่ที่ได้รับความสนใจอย่างมากนี้?
- view:782
Apple ร่วมมือกับผู้พัฒนาเครื่องมือเบราว์เซอร์อื่น ๆ ประกาศเปิดตัว Speedometer 3.0
Apple ร่วมมือกับผู้พัฒนาเครื่องมือเบราว์เซอร์อื่น ๆ ประกาศเปิดตัว Speedometer 3.0 ที่ Apple อธิบายว่า "เป็นวิธีที่ดีที่สุดในการวัดประสิทธิภาพของเบราว์เซอร์ในการทดสอบขณะนี้"
- view:769

10 มังฮวาที่มีมากกว่า 100 ตอน
สำหรับแฟนๆ การ์ตูนและคอมิกส์ที่กำลังมองหาเรื่องราวที่น่าติดตามและเต็มไปด้วยอารมณ์ความรู้สึก, มังฮวาและมันฮัวเป็นตัวเลือกที่ยอดเยี่ยมที่ไม่ควรมองข้าม ด้วยจำนวนตอนที่มากกว่า 100 ตอน, เรื่องราวเหล่านี้ไม่เพียงแต่มอบความบันเทิงยาวนาน แต่ยังเปิดโอกาสให้ผู้อ่านได้ดำดิ่งสู่โลกและตัวละครอย่างลึกซึ้ง ไม่ว่าจะเป็นการผจญภัย, แฟนตาซี, รักโรแมนติก, หรือแม้แต่เรื่องราวชีวิตจริง, แต่ละเรื่องมีเสน่ห์และความเฉพาะตัวที่จะทำให้คุณหลงใหล ในบทความนี้, เราจะพาคุณไปสำรวจ 10 มังฮวา/มันฮัวที่มีมากกว่า 100 ตอนให้อ่าน พร้อมทั้งเปิดประสบการณ์ใหม่ๆ ในโลกของการ์ตูนที่คุณอาจไม่เคยพบเจอมาก่อน
- view:794

Inkitt: การปฏิวัติวงการหนังสือด้วย AI และการลงทุนครั้งใหญ่
Inkitt แพลตฟอร์มการเผยแพร่ตนเองที่เปลี่ยนเกมด้วยการใช้ AI ในการค้นหาและพัฒนาหนังสือขายดี ได้รับการสนับสนุนด้วยเงินทุน 37 ล้านดอลลาร์ พวกเขามีวิสัยทัศน์ที่จะกลายเป็น "ดิสนีย์แห่งศตวรรษที่ 21" โดยการขยายไปยังแพลตฟอร์มสื่อหลากหลายรูปแบบ ซึ่งรวมถึงเกม, หนังสือเสียง, และวิดีโอ นอกจากนี้ยังใช้ AI สร้างเรื่องราวใหม่ๆ ทำให้พวกเขาไม่เพียงแต่เป็นผู้นำในการเผยแพร่หนังสือ แต่ยังเป็นผู้สร้างเนื้อหาที่น่าตื่นเต้นและปรับเปลี่ยนได้
- view:749

โนบุโอะ อุเอะมัตสึ ประกาศอาจไม่แต่งเพลงประกอบเกมเต็มรูปแบบอีกต่อไป
โนบุโอะ อุเอะมัตสึ นักแต่งเพลงชื่อดังผู้สร้างผลงานเพลงประกอบเกม Final Fantasy มาหลายภาค ได้ให้สัมภาษณ์กับสื่อต่างประเทศว่า เขาอาจจะไม่รับงานแต่งเพลงประกอบเกมเต็มรูปแบบอีกต่อไป
- view:798
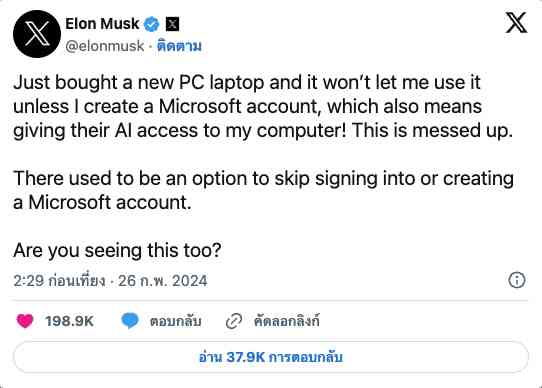
อีลอน มัสก์ วิจารณ์ Windows 11: ผู้ใช้ควรมีสิทธิ์เลือก
อีลอน มัสก์ ซีอีโอของ Tesla และ SpaceX แสดงความไม่พอใจต่อระบบปฏิบัติการ Windows 11 ของ Microsoft ที่บังคับให้ผู้ใช้ลงชื่อเข้าใช้บัญชี Microsoft Account
- view:804

มังฮวา 10 อันดับแรกในปี 2024
มังฮวาเป็นการ์ตูนเกาหลีที่ได้รับความนิยมไปทั่วโลก ด้วยพล็อตเรื่องที่หลากหลาย ตัวละครที่น่าสนใจ และงานศิลปะที่สวยงาม มังฮวามีให้เลือกมากมายสำหรับทุกคน
- view:1084

OpenAI เปิดตัว ChatGPT Team: ยกระดับแชทบอท AI สำหรับทีมขนาดเล็ก
แชทบอท AI เป็นเครื่องมือที่ทรงพลังที่สามารถช่วยให้ธุรกิจขนาดเล็กและกลางทำงานได้อย่างมีประสิทธิภาพมากขึ้น อย่างไรก็ตาม แชทบอท AI ระดับพรีเมียมมักจะมีราคาแพงเกินไปสำหรับธุรกิจขนาดเล็ก OpenAI ตระหนักถึงปัญหานี้ จึงได้เปิดตัว ChatGPT Team แพ็กเกจใหม่สำหรับแชทบอท AI ChatGPT ที่ออกแบบมาสำหรับทีมขนาดเล็ก บทความนี้จะสรุปรายละเอียดของ ChatGPT Team และวิเคราะห์ว่าแพ็กเกจนี้สามารถตอบสนองความต้องการของธุรกิจขนาดเล็กและกลางได้อย่างไร
- view:1060

Netflix Games พุ่งแรง! ในปี 2023
Netflix Games เปิดตัวเมื่อ 2 ปีก่อน ด้วยโมเดลที่แตกต่าง โดยให้ดาวน์โหลดฟรี ไม่มีโฆษณา หรือซื้อภายในแอป ในช่วงแรก เกมของ Netflix ได้รับความนิยมไม่มากนัก แต่ในปี 2023 เกมของ Netflix กลับได้รับความนิยมเพิ่มขึ้นอย่างก้าวกระโดด ดาวน์โหลดเพิ่มขึ้นถึง 180% โดยเกม GTA เป็นตัวขับเคลื่อนหลัก
- view:843

7 ภาพยนตร์ซูเปอร์ฮีโร่ที่ไม่ใช่ของ Marvel
แน่นอนครับ! หากคุณเป็นแฟนตัวยงของภาพยนตร์ซูเปอร์ฮีโร่และกำลังมองหาตัวเลือกที่ไม่ใช่จาก Marvel Cinematic Universe (MCU) นี่คือรายการภาพยนตร์ที่คุณไม่ควรพลาด! แต่ละเรื่องมีเอกลักษณ์เฉพาะตัวและนำเสนอเรื่องราวที่น่าตื่นเต้นในโลกที่แตกต่างกัน ตั้งแต่การปรับเปลี่ยนจากหนังสือการ์ตูนไปจนถึงคลาสสิกที่เป็นที่ต้องดู
- view:839

แนะนำซีรีส์และภาพยนตร์ที่ไม่ควรพลาดบน Disney Plus ปี 2023
ในปี 2023, Disney Plus ยังคงเป็นแพลตฟอร์มที่เต็มไปด้วยภาพยนตร์และซีรีส์คุณภาพจากจักรวาลยอดนิยมอย่าง Marvel และ Star Wars แต่นอกจากนี้ยังมีเนื้อหาใหม่ๆ จาก Avatar และ Doctor Who ที่เพิ่มเติมความหลากหลายให้กับคอลเลกชันของพวกเขา ต่อไปนี้คือรายการของซีรีส์และภาพยนตร์ที่น่าตื่นตาตื่นใจที่คุณไม่ควรพลาดในปีนี้บน Disney Plus
- view:880

ที่สุด 10 เกมในปี 2023
ในปี 2023, การเล่นเกม ได้รับการยกย่องว่าเป็นปีที่ยอดเยี่ยม มีเกมที่น่าสนใจหลายเกมทั้งเกมบล็อกบัสเตอร์และเกมอินดี้ขนาดเล็ก ต่อไปนี้คือรายการของเกมที่ดีที่สุด 10 เกมในปี 2023
- view:760

2023 ประเทศอังกฤษมีความเร็วการดาวน์โหลดข้อมูลผ่านเครือข่าย 5G ที่ช้าที่สุดในหมู่ประเทศ G7
ในปี 2023, ประเทศอังกฤษมีความเร็วการดาวน์โหลดข้อมูลผ่านเครือข่าย 5G ที่ช้าที่สุดในหมู่ประเทศ G7 ตามข้อมูลจาก Opensignal โดยมีความเร็วเฉลี่ยอยู่ที่ 118.2 เมกะบิตต่อวินาที ซึ่งลดลง 13% จากปี 2022 ที่มีความเร็วเฉลี่ยอยู่ที่ 136.5 เมกะบิตต่อวินาที ในขณะที่ฝรั่งเศสมีความเร็วเฉลี่ยสูงสุดในกลุ่มที่ 221.1 เมกะบิตต่อวินาที
- view:840

Apple แชร์โฆษณา iPhone 15 Plus ที่เน้นความทนทานของแบตเตอรี่
Apple ได้แชร์โฆษณาสั้นของ iPhone 15 Plus บนช่อง YouTube ที่เน้นไปที่ความทนทานของแบตเตอรี่ของอุปกรณ์
- view:830

Hyperloop One ปิดตัวลงอย่างเป็นทางการหลังไม่สามารถหาผู้ลงทุนรายใหม่ได้
บริษัท Hyperloop One ซึ่งเป็นบริษัทพัฒนาเทคโนโลยีขนส่งความเร็วสูงแบบสุญญากาศ ได้ประกาศปิดตัวลงอย่างเป็นทางการเมื่อวันที่ 21 ธันวาคม 2023 หลังจากไม่สามารถหาผู้ลงทุนรายใหม่มาสนับสนุนการดำเนินงานของบริษัทได้
- view:983
Apple News
Apple และ The Athletic ประกาศว่าสมาชิก Apple News+ ตอนนี้สามารถเข้าถึงงานข่าวกีฬาที่เหนือกว่าของ The Athletic ได้แล้ว
- view:970

Nubia Z60 Ultra
Nubia Z60 Ultra เปิดตัวอย่างเป็นทางการ มาพร้อมชิป Snapdragon 8 Gen 3 และกล้องใต้จอความละเอียด 44 ล้านพิกเซล
- view:883

NASA ได้ทำสิ่งที่น่าประทับใจ จากอวกาศลึกสู่โลกผ่านเลเซอร์จากระยะทาง 19 ล้านไมล์
NASA ได้ทำสิ่งที่น่าประทับใจด้วยการสตรีมวิดีโอความละเอียดสูง (Ultra-HD) จากอวกาศลึกสู่โลกผ่านเลเซอร์จากระยะทาง 19 ล้านไมล์.
- view:915
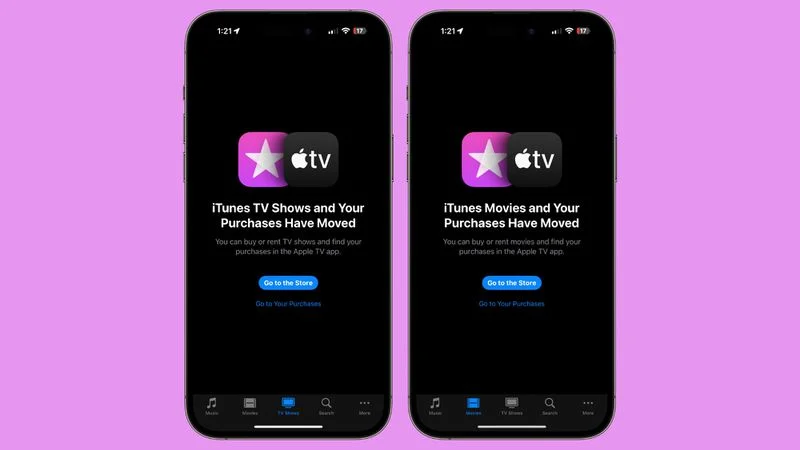
iOS 17.2, iPadOS 17.2 และ tvOS 17.2
แอปเปิลได้ยกเลิกตัวเลือกในการซื้อรายการทีวีและภาพยนตร์จากแอป iTunes Store โดยเปลี่ยนไปใช้แอป Apple TV แทน น่าเสียดายที่การย้ายไปยังแอป Apple TV เพื่อรวมการซื้อและการรับชมทำให้รายการสิ่งที่อยากได้ (wishlist) ไม่มีอีกต่อไป และลูกค้าที่ใช้ฟีเจอร์นี้ไม่ได้รับการแจ้งเตือนเกี่ยวกับการยกเลิกนี้
- view:952

เลขเด็ด 16 ธันวาคม 2566
เลขเด็ด ลอตเตอรี่
- view:847

มีคำสั่งยกเลิกคำสั่งให้ฟื้นฟูกิจการของบริษัท สินมั่นคงประกันภัย จำกัด (มหาชน)
เมื่อวันที่ 15 ธันวาคม 2566 ศาลล้มละลายกลาง มีคำสั่งยกเลิกคำสั่งให้ฟื้นฟูกิจการของบริษัท สินมั่นคงประกันภัย จำกัด (มหาชน) ทำให้บริษัทกลับเข้าสู่สภาวะปกติ โดยอำนาจหน้าที่ในการจัดกิจการ และทรัพย์สินของลูกหนี้ กลับเป็นของผู้บริหารของลูกหนี้ ส่งผลให้สภาวะพักการชำระหนี้สิ้นสุดลง
- view:786
![ซีรีส์เกาหลี “เกมท้าตาย | Death's Game” ซีซั่น 1 [2023] ประสบความสำเร็จอย่างถล่มทลาย](https://ink-mingle.com/backend/public/3073fc78-fa1d-441c-b6c4-0625b60145a0.webp)
ซีรีส์เกาหลี “เกมท้าตาย | Death's Game” ซีซั่น 1 [2023] ประสบความสำเร็จอย่างถล่มทลาย
ซีรีส์เกาหลีเรื่อง “เกมท้าตาย | Death's Game” ซีซั่น 1 ออกอากาศตอนแรกเมื่อวันที่ 15 ธันวาคม 2566 ทางแพลตฟอร์ม Prime Video และได้รับความนิยมอย่างล้นหลาม โดยได้รับคำชมจากนักวิจารณ์และแฟน ๆ มากมาย
- view:689

"Honkai: Star Rail" ตัวอย่างเวอร์ชัน 1.6 "มงกุฎแห่งปุถุชนและเทพเจ้า"
เมื่อวันที่ 15 ธันวาคม 2566 ที่ผ่านมา Honkai: Star Rail เกมมือถือสวมบทบาทแนวไซไฟแฟนตาซีจากค่าย HoYoverse ได้ทำการอัปเดตเวอร์ชัน 1.6 "มงกุฎแห่งปุถุชนและเทพเจ้า" อย่างเป็นทางการแล้ว
- view:984

เว็บไซต์หางานในไทยยอดนิยมในปี 2023
การเลือกเว็บไซต์หางานที่เหมาะสมนั้นขึ้นอยู่กับปัจจัยหลายประการ เช่น ประเภทของงานที่ต้องการสมัคร ประสบการณ์การทำงาน และความถนัดในการใช้เทคโนโลยี สำหรับผู้ที่กำลังมองหางานใหม่ ควรศึกษาข้อมูลเกี่ยวกับเว็บไซต์หางานต่างๆ ให้ดีก่อน เพื่อเลือกเว็บไซต์ที่เหมาะสมกับตนเองมากที่สุด
- view:1023

กำลังใจในการทำงานพรุ่งนี้
ทำงานในแต่ละวันนั้นอาจพบกับความท้าทายและความเครียดได้ แต่การมีทัศนคติที่ดีและการเตรียมตัวที่เหมาะสมสามารถช่วยให้คุณรู้สึกมั่นใจและพร้อมรับมือกับทุกสถานการณ์ได้ ดังนั้น, ในการเตรียมตัวสำหรับวันทำงานพรุ่งนี้, การให้กำลังใจและคำแนะนำที่ดีจะช่วยให้คุณมีพลังและมุมมองที่สดใสยิ่งขึ้น เพื่อช่วยให้คุณมีวันที่เต็มไปด้วยผลสำเร็จและความพึงพอใจในการทำงาน
- view:854

25 สิ่งใหม่ ๆ ที่ iPhone ของคุณสามารถทำได้ด้วยการอัปเดต iOS 17.2 ในเดือนหน้า
ในการอัปเดต iOS 17.2 ที่กำลังจะมาถึง, Apple นำเสนอคุณสมบัติใหม่ๆ ที่น่าตื่นเต้นสำหรับผู้ใช้ iPhone หลายรายการ. การอัปเดตนี้ไม่เพียงแต่เพิ่มความสะดวกสบายและความสามารถในการปรับแต่งให้กับผู้ใช้ แต่ยังรวมถึงการปรับปรุงในด้านความปลอดภัยและความเป็นส่วนตัว. ต่อไปนี้คือภาพรวมของคุณสมบัติใหม่ๆ ที่เราสามารถคาดหวังได้จากการอัปเดตนี้:
- view:974

Apple จะสนับสนุน RCS, ข่าวลือ iPhone 16 และอื่นๆ
ในสัปดาห์นี้ มีข่าวสำคัญหลายประการจาก Apple ที่น่าสนใจ รวมถึงการประกาศที่น่าตื่นตาตื่นใจเกี่ยวกับการรองรับมาตรฐาน RCS สำหรับการสื่อสารที่ดียิ่งขึ้นกับอุปกรณ์ Android นอกจากนี้ยังมีข่าวลือเกี่ยวกับคุณสมบัติใหม่ ๆ ของ iPhone 16 การอัปเดตด้านซอฟต์แวร์ที่น่าตื่นเต้นสำหรับ iOS 18 และอื่น ๆ อีกมากมาย ต่อไปนี้คือรายละเอียดของข่าวแต่ละข้อที่เกี่ยวข้องกับ Apple ในสัปดาห์นี้
- view:926

เบื่องานสุดๆ ทำไงดี
คุณลองใช้แนวทางเหล่านี้ดู และดูว่ามีอะไรที่เหมาะกับคุณบ้าง การรู้สึกเบื่องานบางครั้งอาจเป็นสัญญาณที่บอกว่าคุณต้องการการเปลี่ยนแปลงบางอย่างในชีวิตของคุณ.
- view:959

การพัฒนาตัวเอง 10 วิธี
แนวคิดการพัฒนาตัวเองที่คุณขอมา รวมถึงการอ่านหนังสือ, การฝึกสมาธิ, การออกกำลังกาย, การเรียนรู้ทักษะใหม่, การเขียนวาระส่วนตัว, การเครือข่ายสังคม, การสื่อสารอย่างมีประสิทธิภาพ, การบริหารเวลา, การมีสติ, และการปฏิบัติตนอย่างมีจริยธรรม
- view:964

Angular 17
Angular 17 นำเสนอคุณลักษณะใหม่ๆ หลายอย่าง และนี่คือไฮไลท์บางส่วน:
- view:987

การเตรียมตัวก่อนที่จะถูกหัวหน้าด่า
การเตรียมตัวก่อนที่จะถูกหัวหน้าด่าเป็นสิ่งที่จำเป็นในบางสถานการณ์ เพื่อให้คุณสามารถรับฟังและเรียนรู้ได้ดีขึ้น โดยไม่ทำให้ความรู้สึกของคุณเดือดร้อนมากนัก นี่คือวิธีเตรียมตัว
- view:790

แอปเปิลจะลงทุนหลายพันล้านดอลลาร์ในฮาร์ดแวร์เพื่อสนับสนุนการพัฒนาปัญญาประดิษฐ์ (AI)
แอปเปิลจะลงทุนหลายพันล้านดอลลาร์ในฮาร์ดแวร์เพื่อสนับสนุนการพัฒนาปัญญาประดิษฐ์ (AI) ในปี 2024 ตามที่นักวิเคราะห์ของแอปเปิล มิง-ชี คัว คาดการณ์ คัวคาดว่าแอปเปิลจะใช้จ่ายอย่างน้อย 620 ล้านดอลลาร์สำหรับเซิร์ฟเวอร์ในปี 2023 และ 4.75 พันล้านดอลลาร์ในปี 2024
- view:975

Apple เปิดตัว Apple Pencil รุ่นใหม่พร้อมพอร์ต USB-C และอื่นๆ
Apple ประกาศเปิดตัว Apple Pencil รุ่นประหยัดใหม่ในสัปดาห์นี้ ซึ่งจะวางจำหน่ายควบคู่กับ Apple Pencil รุ่นแรกและ Apple Pencil 2 โดยจะมีให้เลือกในช่วงต้นเดือนพฤศจิกายน โดยมีราคาในสหรัฐอเมริกาที่ 79 ดอลลาร์
- view:1100

8 สิ่งที่ควรรู้เกี่ยวกับ Apple Pencil ใหม่
8 สิ่งที่ควรรู้เกี่ยวกับ Apple Pencil ใหม่
- view:944

5 ระบบปฏิบัติการ (OS) 2023
การเลือกระบบปฏิบัติการที่เหมาะสมนั้นขึ้นอยู่กับความต้องการและความต้องการของผู้ใช้แต่ละคน หากต้องการระบบปฏิบัติการที่ฟรี ปรับแต่งได้สูง
- view:907
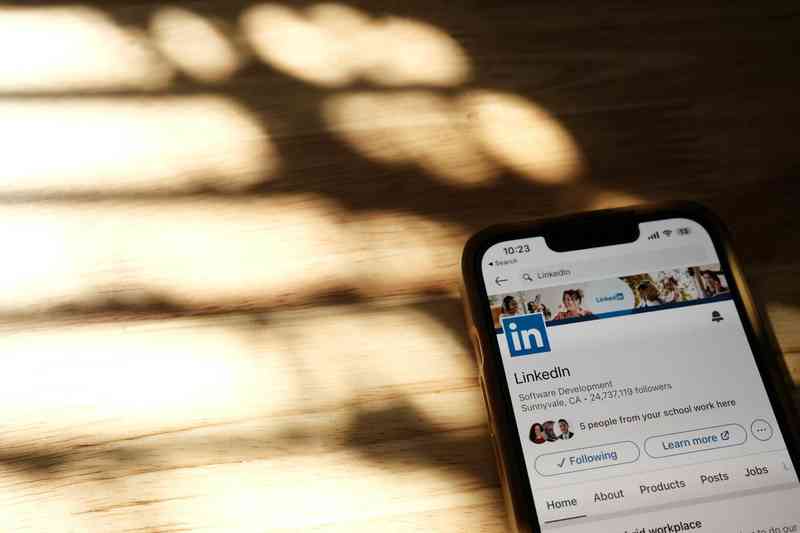
LinkedIn:Microsoft ได้ประกาศลดงานอีกรอบ, โดยมีตำแหน่งงานประมาณ 670 ตำแหน่งที่จะถูกตัดออก
สิ่งนี้มาหลังจากที่ LinkedIn ได้ตัดออกงาน 716 ตำแหน่งในเดือนพฤษภาคม และตามที่มีการลดงานในบริษัทเทคโนโลยีขนาดใหญ่อื่น ๆ
- view:1008

Twitch เพิ่มฟีเจอร์เรื่องราวในแอปมือถือ
ตั้งแต่วันนี้เป็นต้นไป, Twitch จะเริ่มให้พาร์ทเนอร์และพันธมิตรมีตัวเลือกในการสร้างเรื่องราวที่คล้ายกับ Instagram.
- view:1003

LinkedIn ปลดพนักงาน 700 ตำแหน่งและปิดแอปในจีน
LinkedIn, เครือข่ายสังคมออนไลน์สำหรับผู้เชี่ยวชาญในธุรกิจ, ได้ประกาศลดพนักงาน 716 ตำแหน่งจากทั้งหมด 20,000 คน และจะหยุดใช้แอปพลิเคชันสำหรับหางานในจีน โดยตามจดหมายของรายัน โรสแลนสกี, CEO ของบริษัท, เขากล่าวว่ามีเป้าหมายเพื่อปรับปรุงการดำเนินงานของบริษัทให้มีประสิทธิภาพยิ่งขึ้น
- view:965
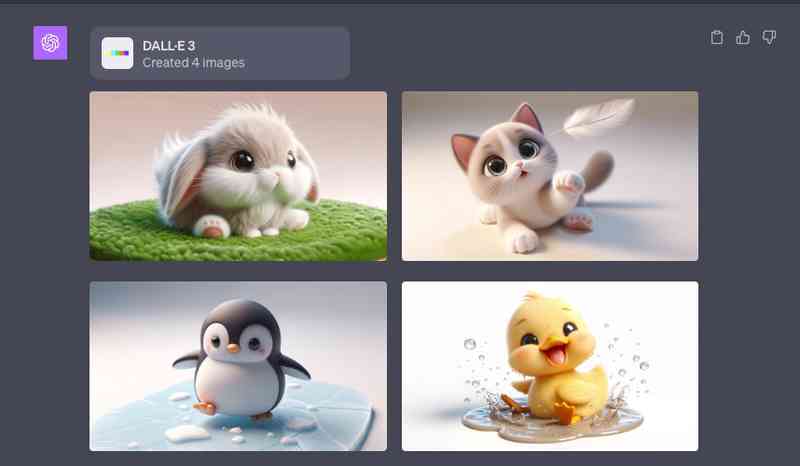
DALL-E 3 มาแล้ว ChatGPT สามารถสร้างรูปภาพได้
DALL-E 3 เป็นเทคโนโลยีสร้างภาพเสมือนจริงที่พัฒนาโดย OpenAI โดยใช้ AI แบบสร้างแบบจำลอง (generative AI) DALL-E 3 สามารถสร้างภาพจากข้อความได้หลากหลายรูปแบบ เช่น ภาพวาด รูปถ่าย กราฟิก ฯลฯ
- view:982

Google Cloud เปิดตัวแล็บ AI แบบสร้างแบบจำลองฟรีใน The Arcade
Google Cloud เปิดตัวแล็บ AI แบบสร้างแบบจำลองฟรีใน The Arcade ซึ่งเป็นแพลตฟอร์มการเรียนรู้แบบ gamified ที่มีเกมใหม่ทุกเดือน เกมต่างๆ จะขึ้นอยู่กับแล็บจาก Google Cloud Skills Boost เพื่อให้ผู้เรียนได้ลงมือปฏิบัติกับเครื่องมือ AI ที่ทรงพลังของ Google Cloud เช่น Vertex AI และ Generative AI Studio
- view:998

Google Cloud เปิดตัวการชดเชย AI แบบสร้างแบบจำลองเพื่อปกป้องลูกค้า
Google Cloud ประกาศเปิดตัวการชดเชย AI แบบสร้างแบบจำลอง (Generative AI Indemnification) ซึ่งเป็นโปรแกรมใหม่ที่ช่วยปกป้องลูกค้าจากความเสียหายที่เกิดจาก AI แบบสร้างแบบจำลอง โปรแกรมนี้ครอบคลุมความเสียหายที่เกิดขึ้นจาก AI แบบสร้างแบบจำลองที่สร้างขึ้นหรือฝึกฝนบน Google Cloud โดยไม่คำนึงถึงสาเหตุ
- view:959

NASA ปล่อยยาน Psyche ไปสำรวจดาวเคราะห์น้อยโลหะเป็นครั้งแรกของประวัติศาสตร์
องค์การบริหารการบินและอวกาศแห่งชาติสหรัฐอเมริกา (NASA) ได้ปล่อยยาน Psyche ไปสำรวจดาวเคราะห์น้อยโลหะ 16 Psyche เป็นครั้งแรกของประวัติศาสตร์ โดยใช้จรวด Falcon Heavy ของ SpaceX ยาน Psyche จะเดินทางไปสำรวจดาวเคราะห์น้อยโลหะ ซึ่งตั้งอยู่ในแถบดาวเคราะห์น้อยระหว่างดาวอังคารและดาวพฤหัสบดี โดยใช้เวลาเดินทาง 6 ปี ระยะทาง 2.2 พันล้านไมล์
- view:1086

Apple TV ได้เติบโตอย่างมากตั้งแต่การเปิดตัว
เมื่อเทียบกับแพลตฟอร์มสตรีมมิ่งอื่น ๆ ในสหรัฐอเมริกา, Apple TV+ ได้เติบโตอย่างมากตั้งแต่การเปิดตัวในปี 2019 แต่ยังคงอยู่เบื้องหลังคู่แข่งหลักอย่าง Netflix และ Amazon Prime Video ตามข้อมูลจาก JustWatch, Amazon Prime Video ยังคงครองอันดับหนึ่งด้วยส่วนแบ่งตลาด 22% (เพิ่มขึ้น 1% จากไตรมาสก่อนหน้า) ในขณะที่ Netflix ตามมาอย่างใกล้ชิดด้วย 21%
- view:1086

New การออกแบบ PS5 ขนาดเล็กใหม่มาพร้อมที่เก็บข้อมูล 1TB สำหรับ PS5 และ PS5 Digital Edition
เมื่อฤดูหยุดยาวใกล้เข้ามา เราตื่นเต้นที่จะแบ่งปันว่าเรามีรุ่น PS5 ใหม่ที่กำลังจะเปิดตัว เพื่อตอบสนองความต้องการที่เปลี่ยนแปลงไปของผู้เล่น ทีมวิศวกรรมและการออกแบบของเราได้ร่วมมือกันในการสร้างรูปแบบใหม่ที่ให้ความเลือกหลากหลายและความยืดหยุ่นมากขึ้น คุณสมบัติเดียวกันที่ทำให้ PS5 เป็นที่สุดสำหรับการเล่นเกมได้ถูกรวมอยู่ในรูปทรงที่เล็กลง พร้อมด้วยไดรฟ์ดิสก์ Ultra HD Blu-ray ที่สามารถติดตั้งเพิ่มเติมได้ และ SSD ขนาด 1TB สำหรับพื้นที่เก็บข้อมูลภายในที่มากขึ้น
- view:949

John Riccitiello CEO ของ Unity ลาออกจากตำแหน่ง
John Riccitiello, CEO ของ Unity Technologies, ได้ประกาศลาออกจากตำแหน่งหลังจากติดตามความขัดแย้งอย่างต่อเนื่องเกี่ยวกับแผน 'ค่าธรรมเนียม Runtime' ที่ทางบริษัทเสนอขึ้นมา ซึ่งได้รับการต่อต้านอย่างรุนแรงจากนักพัฒนาเกมที่ใช้เอนจิน Unity.
- view:925

Apple Vision Pro รองรับอัตราการรีเฟรชสูงสุดถึง 100Hz
ในวันจันทร์ที่ 9 ตุลาคม 2023, บริษัท Apple ได้เปิดเผยข้อมูลสำคัญเกี่ยวกับหูฟัง Vision Pro ที่จะเปิดตัวในปีหน้า ผ่านการอัปเดตล่าสุดของ visionOS beta, ได้มีการยืนยันว่าหูฟังใหม่นี้สามารถรองรับอัตราการรีเฟรชสูงสุดถึง 100Hz.
- view:956

Valve ประกาศไม่มีแผนพัฒนา Counter-Strike 2 สำหรับ macOS
ในวันจันทร์ที่ผ่านมา, Valve ได้แจ้งให้ทราบอย่างเป็นทางการว่าไม่มีแผนที่จะพัฒนาเกม Counter-Strike 2 สำหรับระบบปฏิบัติการ macOS ซึ่งเป็นข่าวไม่ดีสำหรับผู้เล่นเกมที่ใช้ Mac โดยเฉพาะอย่างยิ่งเมื่อเกมนี้เป็นตัวต่อเนื่องจากเกมยิงปืนแนวแรกบุคคลที่ได้รับความนิยมอย่างมากอย่าง Counter-Strike: Global Offensive (CS:GO).
- view:1014

ศาลยกเลิกค่าปรับ 32.5 ล้านดอลลาร์ของ Google ในคดีฟ้องกับ Sonos
ในวันที่ 10 ตุลาคม 2566, ศาลระดับอาญาของรัฐแคลิฟอร์เนียได้ตัดสินใจยกเลิกคำพิพากษาก่อนหน้าที่สั่งให้ Google จ่ายค่าปรับเป็นจำนวนเงิน 32.5 ล้านดอลลาร์สหรัฐฯ ในคดีที่ Sonos ฟ้องว่า Google ละเมิดสิทธิบัตรที่เกี่ยวข้องกับการจัดการลำโพงหลายห้องของ Sonos.
- view:1063
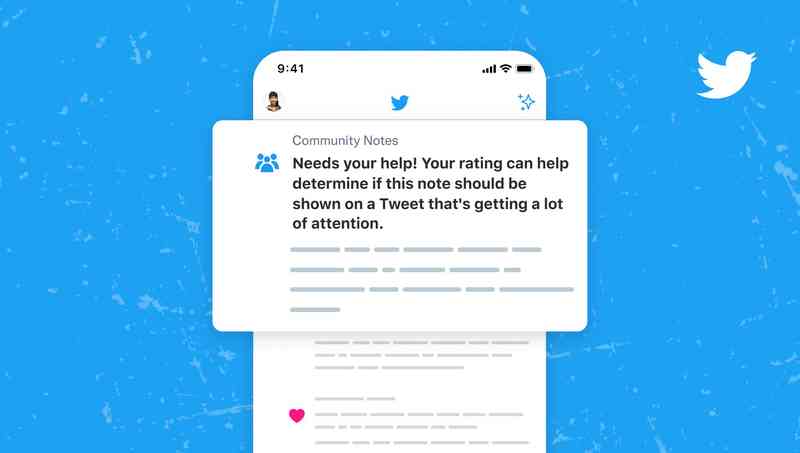
X Community Notes
การทำโฆษณาบนโซเชียลมีเดียสำคัญอย่างยิ่งในยุคปัจจุบัน แต่เกิดปัญหาขึ้นเมื่อ X Community Notes บน X ใช้เป็นเครื่องมือในการคัดค้านและข้อสงสัยต่อเนื้อหาในโฆษณาของบริษัทชั้นนำอย่าง Apple, Samsung, และ Uber ทำให้การโฆษณาบนแพลตฟอร์มนี้ยิ่งยากขึ้น
- view:1030

การประโยชน์ของผักไฮโดรโปนิก: วิธีการเกษตรแบบไม่ใช้ดิน
ไฮโดรโปนิกคือวิธีการเกษตรที่ได้รับความสนใจอย่างแพร่หลายในช่วงเวลาหลัง ๆ โดยเป็นทางเลือกที่แตกต่างจากการเกษตรแบบดั้งเดิม ไฮโดรโปนิกมีส่วนไปทางการผลิตอาหารแบบยั่งยืน บทความนี้จะพิจารณาแนวคิดของไฮโดรโปนิกและดูข้อดีเมื่อเทียบกับการปลูกแบบดั้งเดิม
- view:949

ความผิดพลาดของ iPhone ที่ควรรู้
Apple เป็นบริษัทที่มีชื่อเสียงในการผลิตสินค้าคุณภาพสูง แต่ไม่ได้หมายความว่า iPhone ของ Apple ไม่เคยมีปัญหา ในบทความนี้ เราจะมาทบทวนความผิดพลาดหรือปัญหาที่เกิดขึ้นกับ iPhone ในอดีต
- view:954

5 แอป Android ที่คุณไม่ควรพลาดในสัปดาห์นี้
5 แอป Android ที่คุณไม่ควรพลาดในสัปดาห์นี้ - รีวิวแอป Android
- view:971

Silent Hill: Ascension กำลังจะมา! วางจำหน่ายในวันฮาลโลวีน
สำหรับแฟนๆ ของเกมสยองขวัญ, ข่าวดีมาถึงคุณ! "Silent Hill: Ascension" ซึ่งเป็นภาคต่อของเกมสยองขวัญยอดนิยม "Silent Hill" ได้ประกาศวันวางจำหน่ายอย่างเป็นทางการแล้ว และวันนั้นคือวันฮาลโลวีน 31 ตุลาคม!
- view:1000

SF Symbols: สัญลักษณ์ใหม่จาก Apple สำหรับนักพัฒนา
Apple, บริษัทเทคโนโลยีชั้นนำของโลก, ได้เปิดตัว "SF Symbols" - ชุดสัญลักษณ์ที่ออกแบบมาเพื่อใช้งานร่วมกับระบบปฏิบัติการ iOS, macOS, watchOS และ tvOS ของ Apple โดยเฉพาะ ชุดสัญลักษณ์นี้ถูกสร้างขึ้นเพื่อให้นักพัฒนาสามารถสร้างแอปพลิเคชันที่มีประสบการณ์ผู้ใช้ที่สอดคล้องและเป็นเอกลักษณ์ของ Apple ได้อย่างลงตัว
- view:835
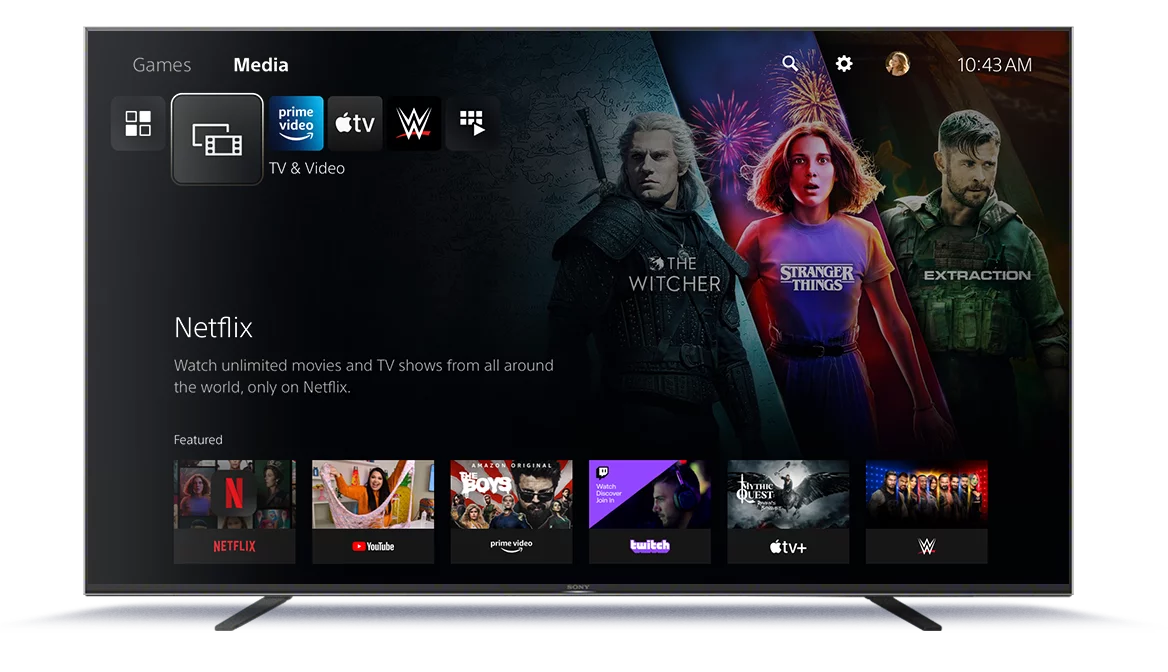
Sony Pictures นำเสนอ "Core" บน PS5 และ PS4 สำหรับสมาชิก PS Plus
Sony Pictures ได้ประกาศเปิดตัวบริการใหม่ที่ชื่อว่า "Core" ซึ่งเป็นบริการสตรีมมิ่งคอนเทนต์วิดีโอที่จะมาพร้อมกับสมาชิก PS Plus บน PS5 และ PS4 โดยไม่มีค่าใช้จ่ายเพิ่มเติม
- view:919

Google ยืนยัน Pixel 8 จะได้รับการสนับสนุนอะไหล่เป็นเวลา 7 ปี
เมื่อ Google เปิดตัวซีรีส์ Pixel 8 ในสัปดาห์นี้, ข่าวสารที่น่าสนใจที่สุดคือการยืนยันว่าโทรศัพท์เหล่านี้จะได้รับการอัปเดตเป็นเวลาสูงสุด 7 ปี ซึ่งรวมถึงการอัปเดตระบบปฏิบัติการ, แพตช์ความปลอดภัย, และการปล่อยฟีเจอร์ใหม่ๆ
- view:667

แอป Gmail มาถึง Wear OS แล้ว!
พร้อมกับการเปิดตัว Pixel Watch 2 ในวันนี้, Google ได้ปล่อยแอป Gmail สำหรับ Wear OS ออกมาหลังจากที่ประกาศไว้เมื่อไม่นานมานี้
- view:1001
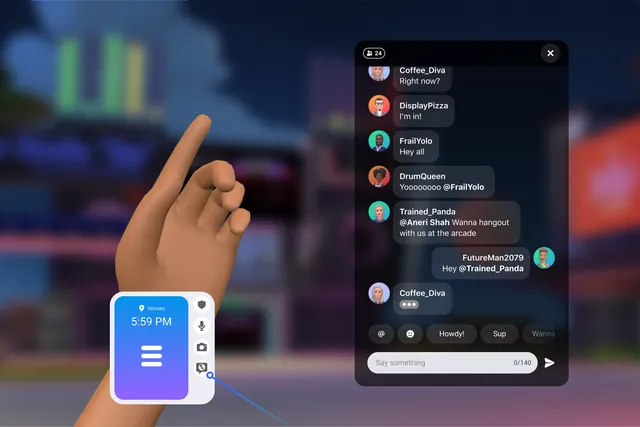
Meta นำเสนอฟีเจอร์แชทข้อความใหม่ใน Horizon Worlds
Meta, บริษัทที่เคยเรียกว่า Facebook, ได้เปิดตัวฟีเจอร์แชทข้อความใหม่สำหรับ Horizon Worlds, โลกเสมือนจริงของเขา. การเปิดตัวนี้เป็นส่วนหนึ่งของแผนการขยายตัวของบริษัทในโลกแห่งความเป็นจริงเสมือน.
- view:956

Netflix ปรับราคาแพ็กเกจไม่มีโฆษณาขึ้น
Netflix, ผู้ให้บริการสตรีมมิ่งยอดนิยม, กำลังวางแผนเพิ่มราคาแพ็กเกจที่ไม่มีโฆษณาในอนาคตใกล้ๆ หลังจากการปิดตัวของการปิดกั้นนักแสดงฮอลลีวูด
- view:859

X Corp. ถูกฟ้องเรื่องการละเมิดสิทธิ์การค้าตราสินค้าด้วยตัวอักษร "X"
X Corp., บริษัทที่ Elon Musk ปรับเปลี่ยนชื่อจาก Twitter, ตอนนี้กำลังเผชิญกับคดีฟ้องเรื่องการละเมิดสิทธิ์การค้าตราสินค้าจากบริษัท X Social Media ซึ่งเน้นบริการโฆษณาและสื่อสังคมออนไลน์
- view:1016

TikTok พิจารณาเปิดแพลนสมาชิกไม่มีโฆษณา ในขณะที่ Meta คิดค้นแนวทางเดียวกัน
TikTok กำลังพิจารณาการนำเสนอแพลนสมาชิกที่ไม่มีโฆษณาสำหรับแอปของตน ตามที่รายงานจากหลายแหล่งข้อมูล ในขณะที่ Meta ก็กำลังพิจารณาวิธีการเดียวกันสำหรับ Facebook และ Instagram
- view:1053

Pattaya International Fireworks Festival 2023
The Pattaya International Fireworks Festival 2023 is scheduled to take place on November 24 - 25, 2023, at Central Pattaya Beach, Chonburi Province. The event, as always, will feature dazzling firework displays, filled with lights, colors, and sounds, spanning over two nights.
- view:1011

Google ปรับเปลี่ยน Chromebook ด้วยการเ introduc รุ่น Chromebook Plus ที่มีความสามารถมากขึ้น
หลังจากที่ Google เปิดตัว Chrome OS และ Chromebook มากว่า 12 ปี บริษัทได้มุ่งมั่นที่จะสร้างแล็ปท็อปที่มุ่งมั่นที่จะเพิ่มความสามารถในการทำงาน ที่ง่ายดาย มีความน่าเชื่อถือ และมีความปลอดภัยสูง และในวันนี้ Google ได้ทำการปรับเปลี่ยน Chrome OS โดยเ introduc รุ่น Chromebook Plus ที่มีความสามารถและคุณสมบัติที่สูงกว่า
- view:969

Python 3.12.0
Python 3.12.0 เป็นรุ่นใหม่ล่าสุดของภาษาโปรแกรมมิ่ง Python และมีคุณสมบัติใหม่ๆ และการปรับปรุงประสิทธิภาพมากมาย คุณสมบัติใหม่ของรุ่น 3.12 ได้แก่
- view:947

Tesla ไม่สามารถจัดงานส่งมอบ Cybertruck ตามเป้าหมายในไตรมาสที่ 3
Tesla ไม่สามารถจัดงานส่งมอบ Cybertruck ในไตรมาสที่ 3 ของปี 2023 ตามที่ CEO Elon Musk หวังไว้ โดย Musk กล่าวในการประชุมผลประกอบการของบริษัทในเดือนเมษายนว่า "เราคาดว่าจะมีงานส่งมอบที่ยอดเยี่ยมในไตรมาสที่ 3"
- view:979

คำเตือน: การชาร์จไร้สาย BMW อาจทำให้ชิป Apple Pay ใน iPhone 15 เสียหาย
ถ้าคุณมี iPhone 15 และขับ BMW, อาจจะดีที่สุดถ้าหลีกเลี่ยงการชาร์จอุปกรณ์ด้วยแผ่นชาร์จไร้สายของยานพาหนะในขณะนี้ ตามที่รายงาน, มีเจ้าของ BMW บางคนที่บ่นว่าชิป NFC ของ iPhone 15 ของพวกเขาหยุดทำงานหลังจากชาร์จอุปกรณ์ด้วยแผ่นชาร์จไร้สายของยานพาหนะ, ตามความคิดเห็นที่แบ่งปันในฟอรัม MacRumors
- view:1032
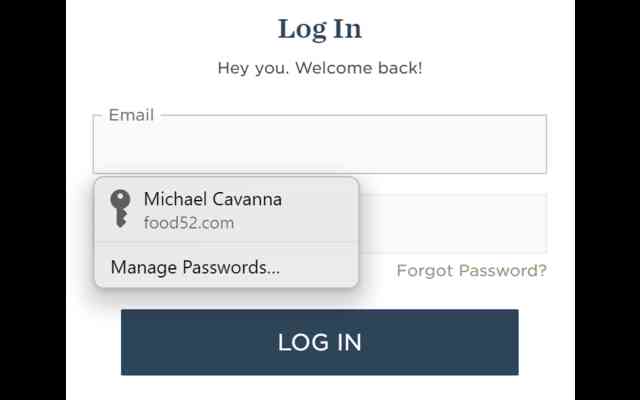
iCloud Passwords Extension
รหัสผ่าน iCloud ช่วยให้คุณป้อนรหัสผ่านจากพวงกุญแจ iCloud ได้เมื่อคุณลงชื่อเข้าเว็บไซต์โดยใช้ Chrome
- view:943
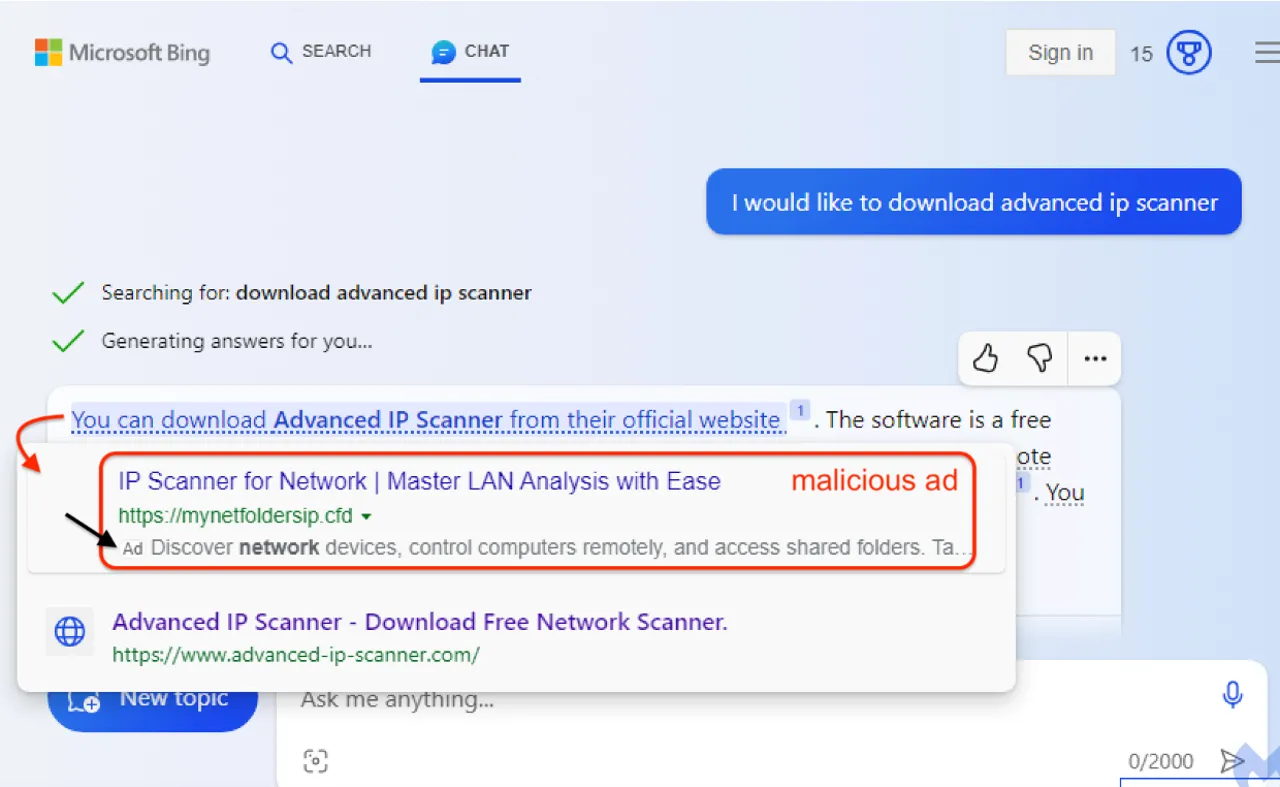
ความระมัดระวังในการใช้ Bing Chat: การตอบกลับอาจมีลิงค์ที่มีมัลแวร์
การใช้งาน Bing Chat อาจนำมาซึ่งความเสี่ยงที่ไม่คาดคิด เนื่องจากมีรายงานว่าการตอบกลับบางประการอาจมีลิงค์ที่นำไปสู่มัลแวร์ ซึ่งสามารถทำให้ข้อมูลส่วนตัวของผู้ใช้งานตกอยู่ในความเสี่ยง
- view:959

AI ที่มีความมนุษย์: การปรากฏตัวของ PIN ที่ Paris Fashion Week โดย Coperni
ในงาน Paris Fashion Week ล่าสุด, Coperni ได้เปิดตัว PIN ที่มีความสามารถในการสร้างความมนุษย์ให้กับ AI ผ่านทางการใช้งานที่ง่ายและสะดวก การนำเสนอนี้ได้ทำให้ผู้ชมได้พบกับประสบการณ์ใหม่ๆ ที่ผสานระหว่างเทคโนโลยีและแฟชั่น
- view:981

Humane AI Pin: อุปกรณ์สวมใส่ที่ทำงานเหมือนสมาร์ทโฟน
Humane AI Pin คืออุปกรณ์ที่สามารถสวมใส่ได้ และทำงานเหมือนกับสมาร์ทโฟน โดยไม่ต้องมีสิ่งวัสดุทางกายภาพ โดยมีการโปรเจคแอปพลิเคชัน, การโทร, และการช่วยเสมอด้วยเสียงบนมือหรือพื้นผิวต่าง ๆ อุปกรณ์นี้ถูกสร้างขึ้นโดยใช้ปัญญาประดิษฐ์ และถูกนำเสนอโดย Imran Chaudhri ผู้ออกแบบชื่อดังจาก Apple และทีมของเขาที่ TED2023 ที่ Vancouver, Canada
- view:977

Raspberry Pi 5 ที่มีการปรับปรุงทุกด้าน พร้อมให้พรีออเดอร์แล้ววันนี้!
Raspberry Pi 5 ได้เปิดตัวและเริ่มรับพรีออเดอร์! มีการปรับปรุงทุกด้าน ทั้งในเรื่องของประสิทธิภาพ ความเร็ว และชิป I/O ที่กำหนดเอง ทำให้ Raspberry Pi 5 มีความสามารถที่หลากหลายและเหมาะสมกับการใช้งานทั่วไป และงานที่ต้องการประสิทธิภาพสูง
- view:898

สามารถพรีออเดอร์ PlayStation Portal Remote Player ได้แล้วที่สุด!
สำหรับแฟนเกมทั้งหลายที่รอคอย ณ ที่นี้คือข่าวดี! PlayStation ได้เปิดตัวเครื่องเล่นเกมพกพาใหม่ล่าสุด ชื่อว่า "PlayStation Portal Remote Player" และล่าสุดลูกค้าสามารถทำการพรีออเดอร์ได้แล้ว!
- view:933
Meta AI: ผู้ช่วยส่วนตัวใหม่ที่ถูกฝึกหัดจากโพสต์ของคุณบน Facebook และ Instagram
Meta ได้เปิดตัว Meta AI ซึ่งเป็นผู้ช่วยส่วนตัวที่มีความสามารถในการทำงานข้ามแอปพลิเคชันทั้งหมดของ Meta รวมถึง Instagram, WhatsApp, และ Facebook ซึ่งผู้ช่วยส่วนตัวนี้มีความสามารถในการให้ข้อมูลที่ผู้ใช้ต้องการ และยังสามารถทำงานข้ามผลิตภัณฑ์และบริการต่างๆ ของ Meta ได้
- view:1018
ChatGPT สามารถท่องอินเทอร์เน็ต
ChatGPT ได้รับการพัฒนาให้สามารถท่องอินเทอร์เน็ตเพื่อค้นหาข้อมูลที่ทันสมัยและมีความน่าเชื่อถือได้ โดยยังมีลิงค์ตรงไปยังแหล่งข้อมูล ซึ่งทำให้ไม่จำกัดเพียงข้อมูลที่มีก่อนเดือนกันยายน 2021 เท่านั้นอีกต่อไป
- view:797

Logitech G และ Playseat ร่วมมือพัฒนา "Challenge X" โคกพิทที่สามารถพับได้สำหรับแฟนๆ ซิมเรซิ่ง
Logitech G ร่วมกับ Playseat ได้เปิดตัวผลิตภัณฑ์ใหม่ที่ชื่อว่า "Challenge X" ซึ่งเป็นโคกพิทสำหรับการแข่งขันซิมเรซิ่งที่สามารถพับได้ ทำให้สามารถเก็บรักษาได้ง่ายและไม่ทำให้เสียพื้นที่มากนัก ผลิตภัณฑ์นี้เหมาะสำหรับผู้ที่มีพื้นที่จำกัด และต้องการความสะดวกสบายในการจัดเก็บ
- view:959

Ray-Ban Meta smart glasses
Meta ร่วมมือกับ EssilorLuxottica ประกาศเปิดตัว Ray-Ban Meta smart glasses รุ่นใหม่ มีการปรับปรุงเสียงและกล้อง, ตัวเลือกกรอบและเลนส์มากกว่า 150 แบบ, น้ำหนักเบาขึ้น และสะดวกสบายมากยิ่งขึ้น ผู้ใช้สามารถไลฟ์สตรีมไปยัง Facebook หรือ Instagram และสื่อสารกับ Meta AI ด้วยเสียง ราคาเริ่มที่ $299 และเปิดให้จองล่วงหน้าแล้วที่เว็บไซต์ของ Meta และ Ray-Ban
- view:985

ฉลองครบรอบ 25 ปี Google: การเดินทางผ่านความทรงจำ
Doodle วันนี้ฉลองครบรอบ 25 ปีของ Google และทั้งที่ทาง Google เรามุ่งมั่นไปทางอนาคต วันเกิดก็ยังเป็นเวลาที่ดีที่จะได้ย้อนกลับไปดูถึงจุดเริ่มต้น 25 ปีที่แล้ว...
- view:1001

Resident Evil 4 บุก iPhone เปิด Pre-Order แล้ว
เกมส์สยองขวัญที่ทุกคนรู้จัก "Resident Evil 4" กำลังจะมาทวงคืนความสนุกให้กับผู้ใช้ iPhone ในราคา $59.99! ราคานี้เทียบเท่ากับที่ Capcom ตั้งไว้สำหรับเครื่องเกมส์คอนโซลอย่าง PlayStation 5 และ Xbox Series X. สำหรับผู้ที่ต้องการสัมผัสความสนุก สามารถพรีออเดอร์ได้ทันทีบน iPhone, iPad, และ Mac
- view:978

xrain สถิติปริมาณน้ำฝนของโลก
XRain เป็นโซลูชันที่ทันสมัยในการรับข้อมูลการตกฝน ซึ่งต่างจากวิธีทดสอบดั้งเดิมที่ใช้ระบบวัดฝน โดยทั่วไป ระบบวัดฝนจะวัดปริมาณฝนที่ตกตรงจุดนั้นๆ และถ้าติดตั้งอย่างถูกต้อง จะให้ข้อมูลที่แม่นยำมาก แต่การประมาณค่าฝนระหว่างจุดวัดฝนสามารถกลายเป็นกระบวนการที่ยากได้ โดยเฉพาะถ้าระยะทางยาวหรือมีความสูงที่ต่างกัน
- view:1015
macOS Sonoma
macOS Sonoma ฟีเจอร์ใหม่และปรับปรุงมากมาย ต่อไปนี้คือบางส่วนที่น่าสนใจ
- view:1008

การทดสอบการตก (Drop Test) ของ iPhone 15 Pro vs iPhone 14 Pro
การทดสอบการตก (Drop Test) ของ iPhone 15 Pro ที่ทำจากไทเทเนียมเทียบกับ iPhone 14 Pro ที่ทำจากสแตนเลสสตีล โดยทดสอบทำในหลายระดับความสูงและมุมต่าง ๆ
- view:1026

หน้าฝนหน้าสดใสด้วย 5 แบรนด์เครื่องสำอางแนะนำ
หน้าฝนเป็นช่วงที่อากาศร้อนชื้น ทำให้ผิวหน้าของเราเกิดความมันและเหงื่อได้ง่าย ส่งผลให้เครื่องสำอางที่เราแต่งหน้าไว้ไหลเยิ้มหรือหลุดลอกได้ง่าย วันนี้เราจึงจะมาแนะนำ 5 แบรนด์เครื่องสำอางที่เหมาะกับการแต่งหน้าในหน้าฝน รับรองว่าจะช่วยเนรมิตลุคสวยสดใสให้กับคุณได้อย่างมั่นใจ
- view:1005

บัวขาว Vs หวังเหยียนหลง
เกิดเหตุการโกลาหล ในช่วงแข่งขัน การชกมวย กติกา คิกบ็อกซิ่ง ในรูปแบบ K-1 ระหว่าง บัวขาว กับ หวังเหยียนหลง ที่เมืองกว่างโจว ประเทศจีน ท่ามกลางผู้ชมในสนามเต็มความจุ 5,000 คน ค่าบัตรเข้าชมริงไซด์ร่วม 49,000 บาทและถ่ายทอดสดไปทั่วประเทศจีน
- view:1061

บอร์ดเกมที่น่าสนใจ 2023
บอร์ดเกมเป็นกิจกรรมที่ได้รับความนิยมเพิ่มขึ้นเรื่อยๆ ในปัจจุบัน บอร์ดเกมเป็นเกมที่เล่นบนกระดาน โดยมีอุปกรณ์ต่างๆ เช่น ลูกเต๋า ไพ่ และตัวหมาก ผู้เล่นจะต้องใช้ทักษะ ความคิด และกลยุทธ์ในการเอาชนะคู่ต่อสู้
- view:1056

iOS 17 กับ iPad
หาก iPad ของคุณไม่สามารถอัปเดตเป็น iOS 17 ได้ อาจเป็นไปได้ว่า iPad รุ่นของคุณไม่รองรับการอัปเดตนี้ หรือ iPad ของคุณอาจมีปัญหาเกี่ยวกับฮาร์ดแวร์หรือซอฟต์แวร์
- view:1055

ปัญหาการถ่ายโอนข้อมูล iPhone 15 มีดังนี้
สาเหตุ: ยังไม่ชัดเจนว่าสาเหตุของปัญหานี้เกิดจากอะไร แต่คาดว่าอาจเกิดจากปัญหาซอฟต์แวร์หรือฮาร์ดแวร์
- view:1123

ปัญหา iPhone 15
***ปัญหาคราบรอยนิ้วมือขอบ iPhone 15 Pro** ผู้ใช้บางรายรายงานว่า iPhone 15
- view:1043

AI Chat Open Assistant Chatbot
AI Chat Open Assistant Chatbot เป็นแชทบอท AI ฟรีจาก OpenAI ซึ่งขับเคลื่อนโดย ChatGPT แชทบอทสามารถตอบคำถามของคุณและให้ข้อมูลที่เกี่ยวข้องกับหัวข้อใดก็ได้ ChatGPT เป็นโมเดลภาษาขนาดใหญ่ที่ได้รับการฝึกฝนเกี่ยวกับชุดข้อมูลข้อความและรหัสขนาดใหญ่ โมเดลสามารถสื่อสารและสร้างข้อความที่เหมือนมนุษย์เพื่อตอบสนองต่อข้อความแจ้งและคำถามที่หลากหลาย
- view:1035

Hurricane Daniel
Hurricane Daniel เป็นพายุเฮอริเคนลูกแรกของฤดูพายุเฮอริเคนแอตแลนติกปี 2023 ก่อตัวขึ้นเมื่อวันที่ 21 กันยายน 2023 บริเวณตอนกลางค่อนไปทางเหนือของมหาสมุทรแอตแลนติก พายุเคลื่อนตัวไปทางตะวันออกและกลายเป็นพายุเฮอริเคนระดับ 1 เมื่อวันที่ 24 กันยายน 2023
- view:993

Cyberpunk 2077
ข้อมูลเกี่ยวกับอัปเดต 2.0 ของเกม Cyberpunk 2077 มีดังนี้
- view:960
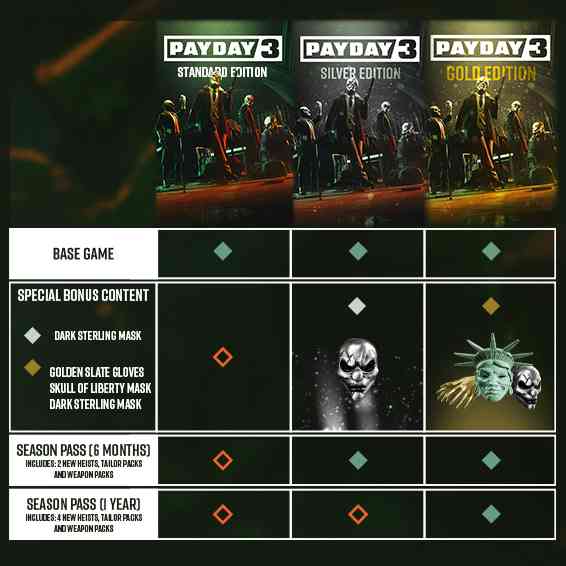
Payday 3
Payday 3 เป็นเกมแนว FPS co-op ภาคต่อของ Payday 2 พัฒนาโดย Overkill Software และวางจำหน่ายโดย 505 Games เกมวางจำหน่ายในวันที่ 21 กันยายน 2023 บน PlayStation 5, Xbox Series และ PC
- view:1025

Sex Education
Sex Education เป็นซีรีส์แนวดราม่าคอเมดี้จากอังกฤษ ความยาว 8 ตอนจบ ว่าด้วยเรื่องราวของ โอทิส เด็กหนุ่มวัยรุ่นธรรมดาๆ ที่บังเอิญไปให้คำปรึกษาเรื่องเพศกับเพื่อนจนโด่งดังไปทั้งโรงเรียน โดยได้รับอิทธิพลบางส่วนมาจากคุณแม่ที่เป็นนักบำบัดทางเพศ
- view:970

Cisco Systems Inc. ได้เข้าซื้อบริษัท Splunk Inc
Cisco Systems Inc. ได้เข้าซื้อบริษัท Splunk Inc. ด้วยมูลค่า 28 พันล้านดอลลาร์สหรัฐ ซึ่งเป็นการเข้าซื้อกิจการที่ใหญ่ที่สุดในประวัติศาสตร์ของ Cisco
- view:1081

อังกฤษเรียกร้อง Meta ชะลอการเปิดตัวฟีเจอร์แชทลับบน Instagram และ Messenger
อังกฤษ - อังกฤษเรียกร้องให้ Meta ชะลอการเปิดตัวฟีเจอร์แชทลับบน Instagram และ Messenger เนื่องจากกังวลว่าฟีเจอร์ดังกล่าวอาจทำให้ยากต่อการปกป้องเด็กจากการล่วงละเมิดทางเพศออนไลน์
- view:1003

บ้านน็อคดาวน์ Vs บ้าน container
บ้านน็อคดาวน์และบ้าน container ต่างก็เป็นบ้านสำเร็จรูปที่มีข้อดีและข้อเสียที่แตกต่างกัน ดังนี้
- view:1031

The First Descendant
ในช่วงเวลานี้, มีการทดสอบเวอร์ชัน OBT (Open Beta Test) ซึ่งจะดำเนินการจนถึงวันที่ 25 กันยายน. นอกจากนี้ยังมีการเปิดเผยตัวละครใหม่ที่ชื่อ "Sharen" ซึ่งเป็นตัวละครที่มีลักษณะเด่นในการควบคุมระยะทางกับศัตรูและสามารถปรากฏตัวและโจมตีศัตรูอย่างไม่คาดคิดได้.
- view:1126
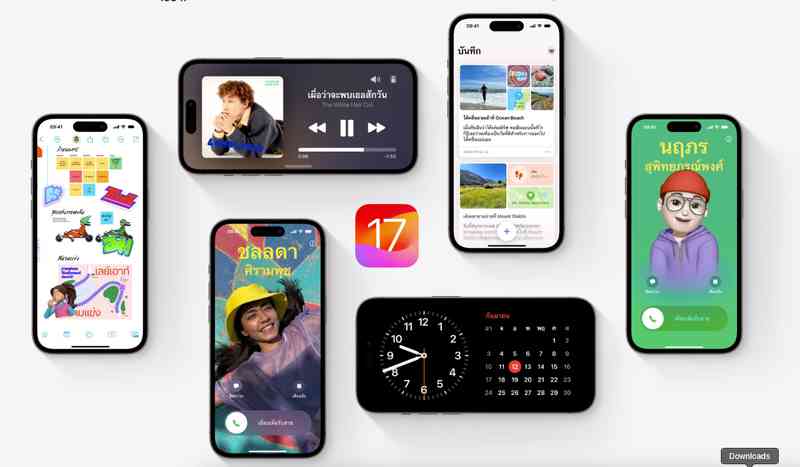
iOS 17 มีอะไรใหม่บ้าง
iOS 17 เปิดตัวเมื่อวันที่ 18 กันยายน 2023 เป็นการอัปเดตครั้งใหญ่สำหรับ iPhone เน้นตอบโจทย์การใช้งานในด้านการสื่อสารและความเป็นส่วนตัว
- view:980

เทศกาล คเณศจตุรถี Ganesh Chaturthi
เทศกาล "คเณศจตุรถี" หรือ "Ganesh Chaturthi" เป็นเทศกาลที่สำคัญของประเทศอินเดีย ซึ่งเป็นการฉลองเพื่อเทือกสรรเพชญ์พระกาเณศ ซึ่งเป็นเทพเจ้าที่มีหัวช้าง ในวันนี้, คนทั้งหลายจะสร้างรูปปั้นพระกาเณศจากดินเหนียว และนำไปสักการะในบ้าน หรือในสถานที่สาธารณะ
- view:1147

เว็บแจกรูปฟรี ใช้ได้เชิงพาณิชย์ได้ 2023
ต่อไปนี้คือเว็บแจกรูปฟรี ใช้ได้เชิงพาณิชย์
- view:1180

Emoji Kitchen 2023
"Emoji Kitchen" ในปี 2023 คือเครื่องมือใหม่ที่ Google นำเสนอ ซึ่งอนุญาตให้ผู้ใช้สร้าง emoji ที่ผสมผสานกันจาก emoji
- view:1112

การเลือกเครื่องพิมพ์ 3D
การเลือกเครื่องพิมพ์ 3D ที่นิยมขึ้นอยู่กับหลายปัจจัย รวมถึง งบประมาณ, ความต้องการในการใช้งาน, และความซับซ้อนของโปรเจคที่คุณต้องการพิมพ์ นี่คือบางประเภทของเครื่องพิมพ์ 3D ที่นิยมในตลาด
- view:1108

ข้อดีข้อเสีย บ้านตู้คอนเทนเนอร์
บ้านตู้คอนเทนเนอร์เป็นแนวคิดในการใช้ตู้คอนเทนเนอร์ที่ใช้สำหรับการขนส่งสินค้าข้ามประเทศเป็นส่วนประกอบของบ้าน ซึ่งมีการแปรรูปเพื่อใช้งานเป็นบ้านอย่างเต็มรูปแบบ ข้อดีและข้อเสียของบ้านตู้คอนเทนเนอร์มีดังนี้:
- view:1082

Canon เปิดตัวกล้อง PTZ ราคาประหยัด
Canon เปิดตัวกล้อง PTZ ราคาประหยัดล่าสุดชื่อ CR-N100 ซึ่งเป็นโมเดลที่ย่อยลงจากรุ่น CR-N300 แต่ยังสามารถบันทึกวิดีโอ 4K
- view:1060

ความแตกต่างระหว่าง IPhone 15 กับ IPhone Pro Max
เปรียบเทียบ IPhone 15 กับ IPhone Pro Max
- view:1076

ผลิตภัณฑ์ Apple ที่จะเปิดตัวใน Apple Event 2023 มีอะไรบ้างมาดูกัน
🌟✨ ต้อนรับสู่ปรากฏการณ์ทางเทคโนโลยีที่ไม่ควรพลาดในปีนี้! ในวันที่ 12 กันยายน 2023, วันที่ทั้งโลกตื่นตาตื่นใจรอคอย, Apple จะเปิดฉากรับประทานความทึ่งทางเทคโนโลยีที่ Apple Event 2023!
- view:1062

EcoFlow WAVE 2 เครื่องปรับอากาศพกพา แอร์เคลื่อนที่ 2023
มื่อมีคลื่นความร้อนเข้ามา, เครื่องปรับอากาศเริ่มดูเป็นสิ่งจำเป็นมากขึ้น ถ้าบ้านหรือพื้นที่ที่คุณอยู่สามารถติดตั้งเครื่องปรับอากาศแบบติดหน้าต่างได้, มันจะเป็นวิธีที่ทรงพลังและประหยัดในการทำให้ห้องเย็นลง แต่มันไม่สามารถใช้งานในทุกบ้านได้ บางทีหน้าต่างของคุณอาจเป็นทางหนีไฟ
- view:1082

แคมป์ปิ้งสุดชิคด้วยสิ่งประดิษฐ์ระดับเลเวลอัพ
การแค้มปิ้งไม่เคยเป็นเช่นนี้มาก่อน! พบกับ"สิ่งประดิษฐ์แค้มปิ้งระดับพรีเมียม"ที่จะปรับปรุงทริปแค้มปิ้งของคุณให้มีความสนุกและสะดวกสบายยิ่งขึ้น ไม่ว่าจะเป็นเท็นท์ที่ตั้งได้เอง หรือเครื่องทำความร้อนแบบพกพา สิ่งประดิษฐ์เหล่านี้จะทำให้การเดินทางในธรรมชาติของคุณน่าจดจำและไม่ธรรมดาที่สุด!
- view:911

ค้นพบแอปพลิเคชันสุดยอดบน iPad Pro ที่จะขยายพลังความสร้างสรรค์และความเป็นมืออาชีพของคุณ
ประสบการณ์ดิจิทัลที่หรูหราและลื่นไหลบน iPad Pro ด้วยแอปพลิเคชันที่เราคัดสรรมาให้คุณ! แบ่งเป็นสี่ประเภทที่ทำให้คุณง่ายต่อการนำไปใช้ในชีวิตประจำวัน: การจดบันทึกและการเขียนบันทึก, การอ่านและความรู้, การจัดการเวลาและผลผลิต, และการสร้างและความสร้างสรรค์. เชิญทางนี้เลยค่ะ!
- view:1294

รายการแอปที่น่าสนใจสำหรับ iPad ในปี 2023
แอพพลิเคชั่นแนะนำให้มีติดเครื่อง ใน ipad ในปี 2023 ที่จะเพิ่มความสะดวกสบายในการใช้งาน
- view:1072

เตือนภัย มิจฉาชีพอ้างโลโก้กรมพัฒนาธุรกิจการค้า
เตือนภัยมิจฉาชีพ ระวัง‼️ มิจฉาชีพอ้างโลโก้กรมพัฒนาธุรกิจการค้า
- view:1103

การจ่ายเบี้ยยังชีพผู้สูงอายุ 2566
การคำนวณอายุของผู้สูงอายุรายเดิม จะคำนวณตามปีงบประมาณ(การเลื่อนรับเบี้ยยังชีพผู้สูงอายุรายเดิมแบบขั้นบันไดจะเลื่อนตามปีงบประมาณ ไม่มีการเพิ่มเบี้ยยังชีพผู้สูงอายุในระหว่างปีงบประมาณ)
- view:1146

เครื่องสำอางน่าสนใจ: สิ่งใหม่ที่คุณควรลองในปี 2023
หลายคนบอกว่า "การแต่งหน้าคือศิลปะ" และในปี 2023 พัฒนาการของเครื่องสำอางเป็นไปอย่างรวดเร็ว ทำให้ผู้ใช้มีโอกาสสัมผัสกับสินค้าและเทคโนโลยีใหม่ๆ วันนี้เรามาดูกันว่ามีสินค้าและเทรนด์เครื่องสำอางไหนบ้างที่คุณควรลอง!